[This is part four of a series of articles about database consolidation. Part one addressed the business drivers and technical challenges, with part two focussing on design choices. Part three was about capacity planning and the concept of overcommitting resources. This section will now look at each resource and see how flash memory helps achieve a better density of databases per consolidation platform.]
Finally we are at the bit where I talk about flash… If you made it this far then you have my unending respect. In this section let’s have a look at the different resources to consider when consolidating databases, focussing particularly on I/O, Memory and CPU. For the I/O piece we need to think about what the requirements are here – and the answer is that we need to have enough space to store our physical data, we need to be able to service the number of I/O requests coming in at any specific time (measured in I/Os Per Second or “IOPS”) and we need to ensure that each I/O request is serviced in a reasonable amount of time (the “latency”). So for clarity let’s list those issues and then address them one by one:
- I/O – Storage Footprint
- I/O – IOPS
- I/O – latency
- Memory
- CPU
I/O – Storage Footprint
Is this the easiest requirement to plan for? Not necessarily, but I would argue that in most cases it is the easiest to change once you are in production (unless you include the process of justifying any extra unplanned cost!). Presenting additional storage (or indeed removing existing storage) is bread and butter for most Operations teams, so whilst it is always better to plan for these things in advance, it isn’t necessarily going to result in downtime or increased risk. Of course, there are exceptions to this – for example with the use of PCIe flash cards expansion is not a trivial exercise (as opposed to the array-based solution preferred by my company Violin Memory, where additional storage can be presented simply by adding arrays as building blocks).
 It’s worth keeping in mind that a consolidation environment will expand in two different dimensions, swallowing up your storage quicker than you might imagine. The individual databases will grow, as all databases inevitably do – but if you are building a true Database-as-a-Service model the number of databases will also grow over time. This is exacerbated by the two-dimensional growth of what I’m going to call the “container”. In a multi-tenancy environment the container will be the software home, plus the diagnostic destination where all those pesky tracefiles reside. In a virtualised environment the container is the VM, with its operating system and swapfile.
It’s worth keeping in mind that a consolidation environment will expand in two different dimensions, swallowing up your storage quicker than you might imagine. The individual databases will grow, as all databases inevitably do – but if you are building a true Database-as-a-Service model the number of databases will also grow over time. This is exacerbated by the two-dimensional growth of what I’m going to call the “container”. In a multi-tenancy environment the container will be the software home, plus the diagnostic destination where all those pesky tracefiles reside. In a virtualised environment the container is the VM, with its operating system and swapfile.
So before you know it all of your space predictions have been smashed. What can you do? Compression and de-duplication techniques can be used to reduce the storage footprint, although it’s worth keeping in mind that compression is essentially a trade-off where CPU resources and latency are sacrificed in order to gain more space. Given that CPU is also on our list of endangered resources, this might not be a great idea. De-duplication isn’t especially effective for databases, but it is very good for backups and virtualised environments. The best answer is to tightly control what goes in to your environement and make sure that storage can be added in a simple and modular manner.
On this line of thought, three important words are housekeeping, ILM and decommissioning (ok ILM isn’t really a word). Houskeeping, because you do not want to find that your system is out of space after some Oracle process (I’m looking at you DIAG) has been spooling massive tracefiles since day one. Running out of space, or indeed any resource, is bad news on a consolidation platform because there is a chance every hosted service will get dragged down as a result. Information Lifecycle Management is important because without a good ILM policy databases quickly turn into dumping grounds for data that refuses to die (we’ve all seen it). And decommissioning, because if your consolidation or DaaS platform is as successful as you hope, everyone will want to be on it… and nobody will want to leave. You have to clear out the dead wood, or those cost savings will never materialise.
What’s the flash angle here? Look at the operational costs of running all of this storage, particularly if you are having to overprovision and/or short-stroke to achieve the required IOPS (see below). How much does it cost to fill your data centre with racks of magnetic disks which have to be spun round at 15k RPM? How much power does that use? How much extra cooling do you need? What’s the price per square foot in your data centre? And most importantly, once you have taken into account all the extra disks you need to achieve the IOPS and latency requirements, what are you really paying for the usable storage?
I/O – IOPS
The term IOPS means I/Os Per Second. The “I/O” part of course means Inputs / Outputs, which we usually assume to mean from storage. In the storage industry people love talking about IOPS, although in the world of DBAs the term is far less prevalent. Another word that the storage industry loves is throughput (also known as bandwidth), which is the volume of data that can be transferred per unit of time, e.g. in megabytes per second. It’s important to understand that there is a simple relationship between IOPS and throughput:
Throughput = IOPS * block size
This means that if you were to perform 1024 IOPS and each operation was on a single 8k database block, the throughput would be 1024 * 8k = 8 MB/sec. (And by the way, if you aren’t used to looking at throughput figures then 8 MB/sec is not a lot… a Violin 6616 array can deliver 4 GB/sec from a single 3U unit). Where things get complicated is when your I/Os are of varying sizes.
When an Oracle database performs a full table scan it performs a db file scattered read which results in I/Os larger than the database block size (in fact usually a multiple of the database block size, with the multiplier being the value of the parameter DB_FILE_MULTIBLOCK_READ_COUNT). At the storage level this means reading sequential blocks – and if you are using rotational media (i.e. spinning magnetic disks) this is good news because you only have to suffer the seek time and rotational latency for the first block. After that point the disk head and spinning platter are in the correct place to read the remaining blocks. So if your system performs a lot of sequential I/O (such as in data warehousing) the storage characteristic you need to think about is probably throughput.
The alternative, lots of random I/O (such as that performed by db file sequential reads during index lookups), is terrible news for rotational media because that means for each block read there will be a seek time and some rotational latency. This reduces the total number of IOPS the system can perform, so if your system performs lots of random I/O (such as in an OLTP environment), the storage characteristic you need to concentrate on is probably IOPS.
Why does that matter here? Well because there is an extremely important observation to be made about the I/O generated by consolidation environments. So important that I’m going to put it on it’s own line:
As you consolidate more databases on to the same storage platform, the I/O will become more random.
This is not new to the world of virtualisation, where it has been known for some time that as you load VMs onto a physical system the underlying I/O becomes increasingly random. It also applies to databases, whether they are virtualised or not.
Since rotational media is so poor with random I/O, the conclusion we can come to is that as you increase the density of your consolidation environment, a disk-based storage system will become increasingly inefficient. Flash memory however has no such issues, because it is non-mechanical. There are no moving parts, no spinning disks and actuator heads to move, so no seek time and no rotational latency. Just lightening-fast I/O. As a result, a flash memory array can deliver a massive rate of IOPS compared to rotating disk array.
Why is this important? Resource limits for one thing – if you consolidate your databases onto a single storage platform then you need to be able to cope with the peak I/O demand of each system – or face performance issues. Worse still, if one database starts performing a lot of I/O you cannot guarantee any quality of service for the other databases… one system could compromise the entire platform.
 A 3.5 inch 15k rpm SAS drive can deliver around 175 IOPS. Put that in a tray of 24 drives (such as a NetApp DS4243) and it will take up 4U and give you around 4,200 IOPS for 14TB of raw capacity. A Violin Memory 6616 flash memory array takes up 3U and gives you 16TB of raw capacity, but is capable of 1,000,000 IOPS. That’s one million versus a little over four thousand…
A 3.5 inch 15k rpm SAS drive can deliver around 175 IOPS. Put that in a tray of 24 drives (such as a NetApp DS4243) and it will take up 4U and give you around 4,200 IOPS for 14TB of raw capacity. A Violin Memory 6616 flash memory array takes up 3U and gives you 16TB of raw capacity, but is capable of 1,000,000 IOPS. That’s one million versus a little over four thousand…
Of course disk array vendors have been around for a long time and so have come up with various coping strategies to mitigate these issues. The most basic strategy is to increase the number of spindles (i.e. the number of drives) therefore increasing the number of available IOPS. This means the number of drives is now based on the IOPS requirement rather than the capacity requirement – we call this overprovisioning. An obvious consequence of this is that you end up paying for far more capacity (as in disk space) than you need, which ruins the price you pay in terms of $ per usable GB. However, since you are buying far more disks, the price you pay in $ per raw GB will probably come down. Guess which one of those prices your disk array vendor will want you to look at? You can’t blame them, it’s just business… but keep your eyes open for the $ per usable GB value. Maybe even look at alternative metrics, like the $ per IOP.
 Another coping strategy employed by disk array vendors is short-stroking. If you thought that overprovisioning sounded inefficient, think again. Consider a disk drive – let’s take the Seagate Cheetah 15K 600GB SAS drive as a fine example of modern rotating disk technology. This thing spins its platter round 15,000 times per minute, which is 250 times per second and as fast as any disk on the market can spin. That means each rotation takes 1/250th of a second, which is 4 milliseconds. So at the point when you want to read your data the disk will need to rotate anything from zero degrees (if you are fortunate and it’s in the right place) to 359.9 degrees (bad luck). Converting that to time, that’s anything from 0ms to 4ms, which is why the spec sheet says the average latency is 2ms (half-way between the best and worst case). Add to that the seek time, i.e. the time taken for the actuator head to move across the disk – which is an average of 3.4 / 3.9 ms for reads / writes – and you have a lot of wasted time. So to compensate for this, in short-stroking only the outer part of the disk is used to store data. This has two key advantages in performance: firstly the average seek time is reduced because the head never needs to move to the inner part of the disk; secondly the average throughput is increased because the outer part of the disk contains more sectors, so more data can be read or written per rotation. To achieve better latency and throughput from short-stroking, typically only 25% of the disk is usable although this can reduce further – 10% usable is not uncommon.
Another coping strategy employed by disk array vendors is short-stroking. If you thought that overprovisioning sounded inefficient, think again. Consider a disk drive – let’s take the Seagate Cheetah 15K 600GB SAS drive as a fine example of modern rotating disk technology. This thing spins its platter round 15,000 times per minute, which is 250 times per second and as fast as any disk on the market can spin. That means each rotation takes 1/250th of a second, which is 4 milliseconds. So at the point when you want to read your data the disk will need to rotate anything from zero degrees (if you are fortunate and it’s in the right place) to 359.9 degrees (bad luck). Converting that to time, that’s anything from 0ms to 4ms, which is why the spec sheet says the average latency is 2ms (half-way between the best and worst case). Add to that the seek time, i.e. the time taken for the actuator head to move across the disk – which is an average of 3.4 / 3.9 ms for reads / writes – and you have a lot of wasted time. So to compensate for this, in short-stroking only the outer part of the disk is used to store data. This has two key advantages in performance: firstly the average seek time is reduced because the head never needs to move to the inner part of the disk; secondly the average throughput is increased because the outer part of the disk contains more sectors, so more data can be read or written per rotation. To achieve better latency and throughput from short-stroking, typically only 25% of the disk is usable although this can reduce further – 10% usable is not uncommon.
Now, for the flash angle, think about all of those disk drives. With overprovisioning and short-stroking in place to achieve the required number of IOPS, you probably have many orders of magnitude the amount of space that you need. That might not be a problem in itself, but all of those disk drives have to be powered, they all produce heat and noise, they all take up expensive physical rack space in the data centre. To fulfil a requirement for one million IOPS you may have to buy and run many racks of disks, whole floor tiles dedicated to spinning round those little metal platters 21.6 million times per day, every day. Or you could buy a single 6616 flash memory array which uses a fraction of the power, generates a fraction of the heat and takes up just 3U. That’s the flash angle – it’s a no brainer.
I/O – Latency
Latency is like the application stealth tax. Every I/O on your system has to suffer this time penalty, so whilst it might look like a small price to pay when you consider a single I/O, it soon stacks up. When you look at your whole system over a period measured in hours you will be shocked to find out how much time you are losing to I/O. Look at this AWR report from the busy CRM system behind a European insurance company’s call centre:
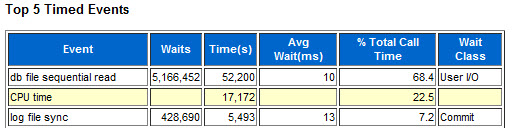
The AWR report was for a 15 minute snapshot and the database was running on a server with 96 cores. The average latency of 10ms meant that in total there were 52,200 seconds lost waiting on db file sequential read (i.e. index lookups, which means random I/O). That’s 870 minutes of CPU time for every minute of elapsed time. To put that another way, for every hour on the wall clock, 58 hours are lost waiting on I/O.
That in itself is a good reason to switch to flash memory and reap the benefits of a sub-millisecond latency. Even if the flash memory array could only deliver 1ms latency (and it will easily deliver lower than that) that’s a tenfold improvement, saving around 52 hours of wait time per hour of elapsed time.
But that’s the standard story of how flash accelerates database applications. Where is the relevance to consolidation? The answer lies in the predictable nature of latency on flash memory – and Violin in particular.
On a disk storage system latency will go through the roof when you reach near-capacity. Flash systems have predictable latency with near-linear increase. Violin is particularly good at this due to the nature of the vRAID technology which protects against the write-cliff (an interesting subject, but this post is long enough without me delving into that). Using SLOB I can generate a latency versus IOPS graph for the 6232 MLC array I currently have in my lab to prove this very point:
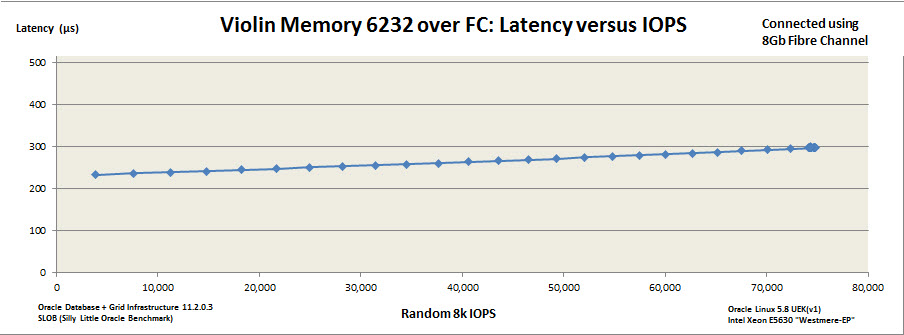
Even when I completely max out the server (I only have limited CPU power here – if I had more the array would easily keep going) I can’t push that latency up over 300 microseconds – and the performance is totally predictable. And that’s the value to a consolidation environment – no matter what the individual systems are doing they cannot compromise the storage system. Flash gives me better performance, but it also reduces the impact of problems. To put it in the language of CIOs, flash both increases my agility and reduces my risk.
Memory
 If you have never experienced a database consolidation environment before it won’t necessarily be obvious, but memory is often the biggest resourcing problem. DRAM prices are more stable than they used to be, but it is still an expensive resource if you want to use it by the terabyte. It also adds considerably to the cost of the server in which it is placed, requiring more power and producing more heat. In part three of this series I talked about the practice of overcommitting resources, which assumes that your individual databases won’t all require their maximum resource utilisation at the same time. For a virtualised environment you can overcommit the memory of the VM operating systems, in fact this is a practice that has been around for years. But how to you overcommit the memory used by the database instances?
If you have never experienced a database consolidation environment before it won’t necessarily be obvious, but memory is often the biggest resourcing problem. DRAM prices are more stable than they used to be, but it is still an expensive resource if you want to use it by the terabyte. It also adds considerably to the cost of the server in which it is placed, requiring more power and producing more heat. In part three of this series I talked about the practice of overcommitting resources, which assumes that your individual databases won’t all require their maximum resource utilisation at the same time. For a virtualised environment you can overcommit the memory of the VM operating systems, in fact this is a practice that has been around for years. But how to you overcommit the memory used by the database instances?
As every DBA knows, the Oracle database instance has two main memory structures, the SGA and the PGA. The SGA always used to be a fixed size, but recent versions of Oracle allowed it to vary based on requirement up to a predefined maximum size. The current version of Oracle now allows the same thing to happen with the PGA as well, meaning a predefined limit can now be set for the total of SGA + PGA, with the individual components varying in size based on workload – but never exceeding the limit.
Here’s a simple question for anyone who has worked with database products in the past… no, in fact, anyone who has worked with any software product at all. Do you want to trust your availability and service levels to a whole host of automatic memory management systems? I don’t. That’s not a criticism about software quality, just a simple statement of risk – I cannot afford the risk of not being in control.
There is an alternative though – the flash angle. The majority of most SGAs will be dedicated to database buffer cache – a portion of memory holding cached copies of data blocks. Database performance, as a science has been built around the fact that reads from memory (logical reads) are faster than reads from disk (physical reads). What happens if you replace the disk with flash? What happens if the physical read time reduces by orders of magnitude?
Disk access times are measured in milliseconds. Flash access times are measured in microseconds. Ok so DRAM access times are measured in nanoseconds, we aren’t going to throw away the buffer cache entirely – plus we have to acknowledge that when Oracle performs a physical read it has to take out latches, manipulate a whole load of doubly-linked lists, pin blocks and do many other things only very clever people understand (but you can be one of them by reading this excellent book) – all of which adds to response time. But the fundamental point remains, if flash allows for a significantly better response time, some of the stuff in that buffer cache can probably now afford to be “dropped” down to the storage layer. (Or as an alternative consideration, a second level of buffer cache could be created on flash using Oracle Database Smart Flash Cache.)
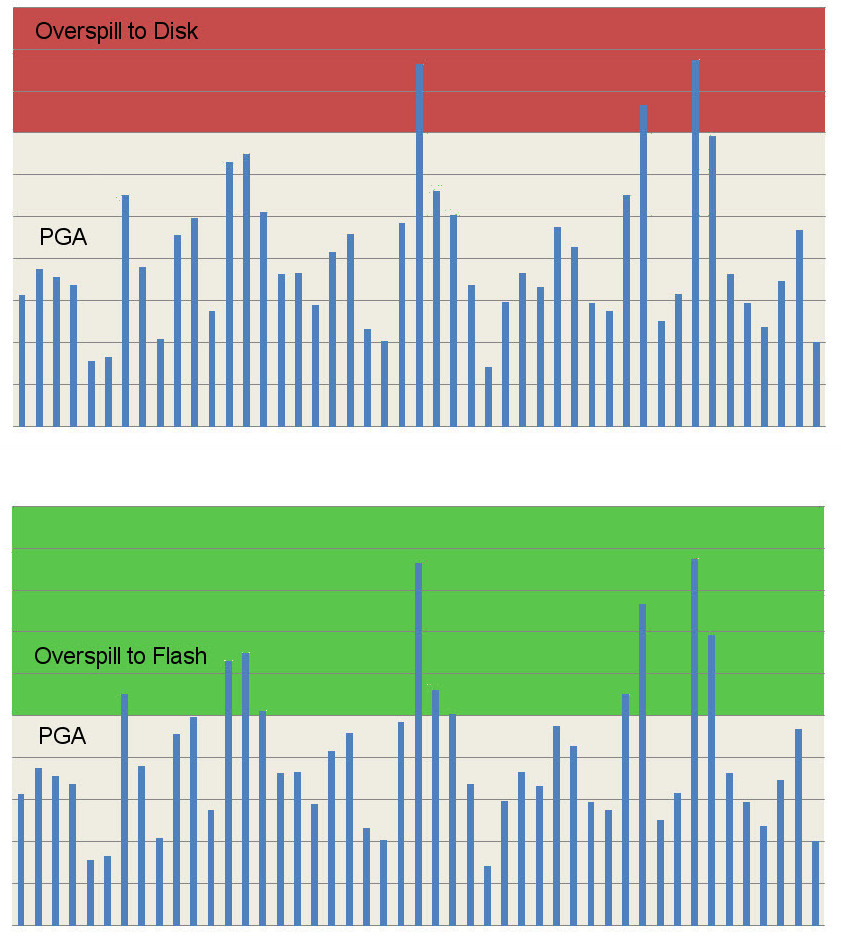 What about the PGA? It’s a similar story, one of the sets of components of the PGA are the SQL Work Areas which includes the sort area, hash area and bitmap merge area. Memory intensive operations such as sorts use this dedicated memory, but if the area size is exceeded they have to spill over to disk (e.g. the temporary tablespace). I am not suggesting that flash is fast enough so that this overspill can now be tolerated for all workloads; it will still be faster to perform sorts, for example, in memory. But when sizing these areas it is normal to pick a value that will encompass most tasks and then accept that there will be a few outliers which spill over to disk. With flash, the penalty paid for that overspill is much lower, which means that more outliers can be tolerated.
What about the PGA? It’s a similar story, one of the sets of components of the PGA are the SQL Work Areas which includes the sort area, hash area and bitmap merge area. Memory intensive operations such as sorts use this dedicated memory, but if the area size is exceeded they have to spill over to disk (e.g. the temporary tablespace). I am not suggesting that flash is fast enough so that this overspill can now be tolerated for all workloads; it will still be faster to perform sorts, for example, in memory. But when sizing these areas it is normal to pick a value that will encompass most tasks and then accept that there will be a few outliers which spill over to disk. With flash, the penalty paid for that overspill is much lower, which means that more outliers can be tolerated.
While we are on the subject of resources let me ask you a question. Why do you have DRAM in your server? You have CPUs to do the work, you have storage to keep persistent data, you have a network to allow remote entities (e.g. users) to drive the CPUs and access that data, maybe modify it too. But why is the DRAM there? After all, nothing stored in DRAM is persistent, so why bother with it in the first place? The answer relates to the processors – the workers that are responsible for making your system more than just a lump of dead electronics. You have DRAM to increase the utilisation of your processors. If you had no DRAM then your processors would be under-utilised because they would be constantly waiting on the high latencies associated with accessing data on storage. That’s a fact worth considering when you ask yourself what you would do differently with a ultra-low latency flash system. I’m not suggesting that you ditch DRAM entirely, but it’s a simple fact that the larger your memory structures, the more processing overhead has to go into managing them. Maybe the need for multi-terabyte database servers isn’t quite a strong as some of your hardware vendors would have you believe?
Flash memory gives you the ability to condense the memory footprint of a database instance beyond the point at which a disk-based database would start to exhibit performance issues. The consequence of this is that by using flash memory you can achieve a greater density of database instances per physical server without having to use additional DRAM.
CPU
 Finally we come to CPU utilisation. It seems obvious that if you take all of your database environments and consolidate them onto one platform you will need a lot of CPU power to ensure they all coexist peacefully. This is where you really want to be able to overcommit, because CPUs are expensive. Maybe not as hardware components (although they certainly aren’t cheap), but as the major contributor to license cost. Oracle licenses most of its database software by the core, with a “multiplication factor” applied based on the type of processor. If you add more cores then you will probably need to buy more licenses for Oracle Database Enterprise Edition, more licenses for Oracle RAC, more tuning and diagnostic pack licenses, perhaps more Partitioning licenses… and any other of the options that you might be using. Active Data Guard, Advanced Compression, Advanced Security, Spatial… it all adds up! On the other hand, if you do not have enough cores then your databases will start fighting each other for resource and you will suffer all sorts of performance problems. It’s a difficult balance. Virtualisation is one possibility because you can soft partition to limit the CPU usage of each VM, but that doesn’t help with the licensing. Oracle does not recognise soft partitioning as a means for limiting the number of software licenses required, so although you can use Oracle VM with hard partitioning you are not going to be able to reduce license cost with VMware.
Finally we come to CPU utilisation. It seems obvious that if you take all of your database environments and consolidate them onto one platform you will need a lot of CPU power to ensure they all coexist peacefully. This is where you really want to be able to overcommit, because CPUs are expensive. Maybe not as hardware components (although they certainly aren’t cheap), but as the major contributor to license cost. Oracle licenses most of its database software by the core, with a “multiplication factor” applied based on the type of processor. If you add more cores then you will probably need to buy more licenses for Oracle Database Enterprise Edition, more licenses for Oracle RAC, more tuning and diagnostic pack licenses, perhaps more Partitioning licenses… and any other of the options that you might be using. Active Data Guard, Advanced Compression, Advanced Security, Spatial… it all adds up! On the other hand, if you do not have enough cores then your databases will start fighting each other for resource and you will suffer all sorts of performance problems. It’s a difficult balance. Virtualisation is one possibility because you can soft partition to limit the CPU usage of each VM, but that doesn’t help with the licensing. Oracle does not recognise soft partitioning as a means for limiting the number of software licenses required, so although you can use Oracle VM with hard partitioning you are not going to be able to reduce license cost with VMware.
But there’s a flash angle here. What if you could increase the efficiency with which you utilise your CPUs? What if your system could use the same processors to do more real work? Flash memory allows this, because it can be used to reduce the amount of time processes spend waiting on I/O.
The iostat manpage defines IOWAIT as:
%iowait: the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request
This is interesting because in this definition the CPUs are otherwise idle. However, don’t be fooled – because this idle state is down to the fact that no more work can be done until the outstanding I/O request has been completed. A good example of this would be a database process waiting on db file sequential read (an index read, manifesting as a random I/O request on the storage system). If the database process is performing an index lookup then the next step is to manipulate the block into the buffer cache, so it cannot continue until the index data block has been retrieved from storage. Asynchronous I/O will not help here, there is nothing more that can be done until the index information has been retrieved.
Maybe this is easier to look at from a database wait interface perspective. Go back to the I/O Latency section above where I showed the AWR report waiting on db file sequential reads. That wait time is lost application time, it’s time that could have been spent doing real work if it wasn’t waiting on I/O.
 Time… that’s what this is really about. If you think about it at a high level, the maximum amount of work that can be done on any system in a given time is dependant on the number of CPUs, since they are the entities performing the work. If you have 16 CPUs then you can perform a maximum of 16 hours of work in one hour of elapsed (wall clock) time. A proportion of that time will be spent waiting on I/O – and that is the time which is lost to the application. Replacing disk with flash memory means reducing the time spent waiting on I/O, which in turn means that a higher proportion of the maximum available time can be spent working.
Time… that’s what this is really about. If you think about it at a high level, the maximum amount of work that can be done on any system in a given time is dependant on the number of CPUs, since they are the entities performing the work. If you have 16 CPUs then you can perform a maximum of 16 hours of work in one hour of elapsed (wall clock) time. A proportion of that time will be spent waiting on I/O – and that is the time which is lost to the application. Replacing disk with flash memory means reducing the time spent waiting on I/O, which in turn means that a higher proportion of the maximum available time can be spent working.
Summary
So, database consolidation on flash memory – whether it be through a shared-platform or by use of virtualisation technologies – allows for more efficient utilisation of resources. Specifically it:
- Provides the necessary storage capacity without having to overprovision expensive disk arrays, therefore reducing operational expenditures such as power, cooling and data centre footprint
- Allows for more I/O operations to be performed per second, allowing for more databases to be consolidated per platform
- Provides not only better latency but also protection from unpredictable latency when experiencing peak loads
- Allows for a reduction in memory requirements, meaning that more instances can fit in the same amount of physical memory
- Increases the utilisation of a system’s CPUs by reducing the amount of time spend waiting on I/O
The conclusion therefore is that consolidating on flash memory increases agility by allowing for a greater density of databases to be achieved on the underlying infrastructure; it reduces risk by offering better protection against peak capacity issues; and it reduces cost in comparison to disk by requiring less power, less cooling and less of that valuable space in the data centre.
More agility, less risk, lower cost. Now who wouldn’t want that?

Nice series of articles, I read every word! One thing that is missing (for me) is the mention of comparative cost. You wrote: “A 3.5 inch 15k rpm SAS drive can deliver around 175 IOPS. Put that in a tray of 24 drives (such as a NetApp DS4243) and it will take up 4U and give you around 4,200 IOPS for 14TB of raw capacity. A Violin Memory 6616 flash memory array takes up 3U and gives you 16TB of raw capacity, but is capable of 1,000,000 IOPS.”
I am not looking for absolute costs because that depends on the negotiation skills of the purchaser, but some rough guide to the difference would enhance the article, and help me personally. Is the Violin array twice the cost, ten times, 1.2 times? What?
Hi Mark
Thanks for your superhuman effort in reading the whole thing, I realise that I may have robbed you of many hours of your life. This is a personal blog and not moderated by my employer Violin Memory, but at the same time there are some rules I have to stick to… and of course (publicly) discussing pricing is one of them.
I know you said you weren’t looking for absolute costs, just a rough guide… but since I very much enjoy my job I’m not too keen on exploring just how close I can get to breaking that rule. Which is a shame because I entirely agree with you, it would add to the article if I could illustrate to you just how cost effective flash has now become.
The array I mentioned in the article above is the 6616 model, which contains 16TB raw of SLC (single level cell) flash. This is what we term “performance flash” and is the top of the range solution, giving the lowest latency, highest IOPS and therefore costing a higher price. The 6232 model, which contains 32TB raw MLC (multi level flash), is what we term “capacity flash”. As a very rough guide it is half the IOPS, double the capacity and half the price (in the same-sized 3U chassis). On consideration it is this MLC product that is probably the most ideal for a consolidation platform, giving a better price per capacity value – although as I stated in the article, $/GB can be very misleading.
From your IP address I am able to see the organisation for which you work, which is one that I know we are currently speaking to both here and in the EMEA headquarters, so hopefully it won’t be long before you get the answer to your question!
Thank you for sharing your thoughts on this subject via a series of articles. It was very informative indeed. One thing I would like to find out is that when we are consolidating using database virtualization (either VMWare or OVM) and databases are configured to use Huge Pages, should memory ballooning be disabled at the hypervisor level?
Personally I would not use memory ballooning if you are virtualizing databases.