
Storage for DBAs: In a recent news article in the UK, supermarket giant Tesco said it threw away almost 30,000 tonnes of food in the first half of 2013. That’s about 33,000 tons for those of you who can’t cope with the metric system. The story caused a lot of debate about the way in which we ignore the issue of wasted food – with Tesco being both criticised for the wastage and praised for publishing the figures. But waste isn’t a problem confined to just the food industry. The chances are it’s happening on your data centre too.
Stranded Capacity
As a simple example, let’s take a theoretical database which requires just under 6TB of storage capacity. To avoid complicating things we are going to ignore concepts such as striping, mirroring, caching and RAID for a moment and just pretend you want to stick a load of disks in a server. How many super-fast 15k RPM disk drives do you need if each one is 600GB? You need about ten, more or less, right? But here’s the thing: the database creates a lot of random I/O so it has a peak requirement for around 20,000 physical IOPS (I/O operations per second). Those 600GB drives can only service 200 IOPS each. So now you need 100 disks to be able to cope with the workload. 100 multiplied by 600GB is of course 60TB, so you will end up deploying sixty terabytes of capacity in order to service a database of six terabytes in size. Welcome to over-provisioning.

Now here’s the real kicker. That remaining 54TB of capacity? You can’t use it. At least, you can’t use it if you want to be able to guarantee the 20,000 IOPS requirement we started out with. Any additional workload you attempt to deploy using the spare capacity will be issuing I/Os against it, resulting in more IOPS. If you were feeling lucky, you could take a gamble on trying to avoid any new workloads being present during peak requirement of the original database, but gambling is not something most people like to do in production environments. In other words, your spare capacity is stranded. Of your total disk capacity deployed, you can only ever use 10% of it.
Of course, disk arrays in the real world tend to use concepts such as wide-striping (spreading chunks of data across as many disks as possible to take advantage of all available performance) and caching (staging frequently accessed blocks in faster DRAM) but the underlying principle remains.
Short Stroking
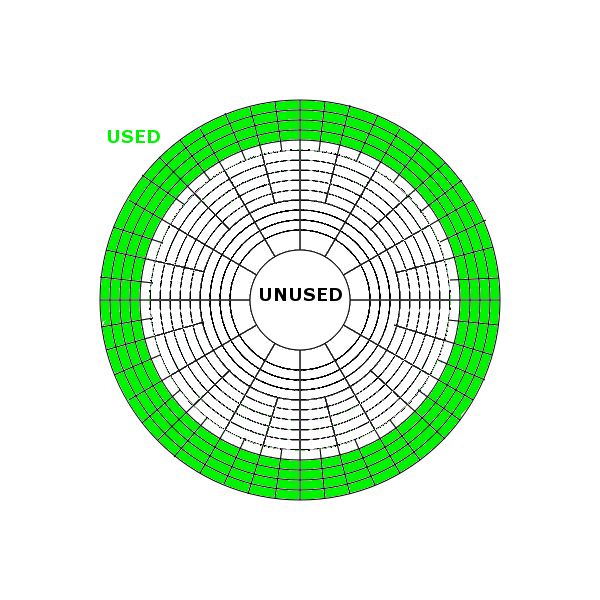
If that previous example makes you cringe at the level of waste, prepare yourself for even worse. In my previous article I talked about the mechanical latency associated with disk, which consists of seek time (the disk head moving across the platter) and rotational latency (the rotation of the platter to the correct sector). If latency is critical (which it always, always is) then one method of reducing the latency experienced on a disk system is to limit the movement of the head, thus reducing the seek time. This is known as short stroking. If we only use the outer sectors of the platter (such as those coloured green in the diagram here), the head is guaranteed to always be closer to the next sector we require – and note that the outer sectors are preferable because they have a higher transfer rate than the inner sectors (to understand why, see the section on zones in this post). Of course this has a direct consequence in that a large portion of the disk is now unused, sometimes up to 90%. In the case of a 600GB disk short stroking may now result in only 60GB of capacity, which means ten times as many disks are necessary to provide the same capacity as a disk which is not short stroked.
Two Types of Capacity
When people talk about disk capacity then tend to be thinking of the storage capacity, i.e. the number of bytes of data that can be stored. However, while every storage device must have a storage capacity, it will also have a performance capacity – a limit to the amount of performance it can deliver, measured in I/Os per second and/or some derivative of bytes per second. And the thing about capacities is that bad things tend to happen when you try to exceed them.

In simplistic terms, performance and storage capacity are linked, with the ratio between them being specific to each type of storage. With disk drives, the performance capacity usually becomes the blocker before the storage capacity, particularly if the I/O is random (which means high numbers of IOPS). This means any overall solution you design must exceed the required storage capacity in order to deliver on performance. In the case of flash memory, the opposite is usually true: by supplying the required storage capacity there will be a surplus of performance capacity. Provide enough space and you shouldn’t need to worry about things like IOPS and bandwidth. (Although I’m not suggesting you should forego due diligence and just hope everything works out ok…)
Waste Watching

I opened with a reference to the story about food wastage – was it fair to compare this to wasted disk capacity in the data centre? One is a real world problem and the other a hypothetical idea taking place somewhere in cyberspace, right? Well maybe not. Think of all those additional disks that are required to provide the performance capacity you need, resulting in excess storage capacity which is either stranded or (in the case of short stroking) not even addressable. All those spindles require power to keep them spinning – power that mostly comes from power stations burning fossil fuels. The heat that they produce means additional cooling is required, adding to the power draw. And the additional data centre floor space means more real estate, all of which costs money and consumes resources. It’s all waste.
And that’s just the stuff you can measure. What about the end users that have to wait longer for their data because of the higher latency of disk? Those users may be expensive resources in their own right, but they are also probably using computers or smart devices which consume power, accessing your database over a network that consumes more power, via application servers that consume yet more power… all wasting time waiting for their results.
Wasted time, waster money, wasted resources. The end result of over-provisioning is not something you should under-estimate…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

One thought on “Understanding Disk: Over-Provisioning”