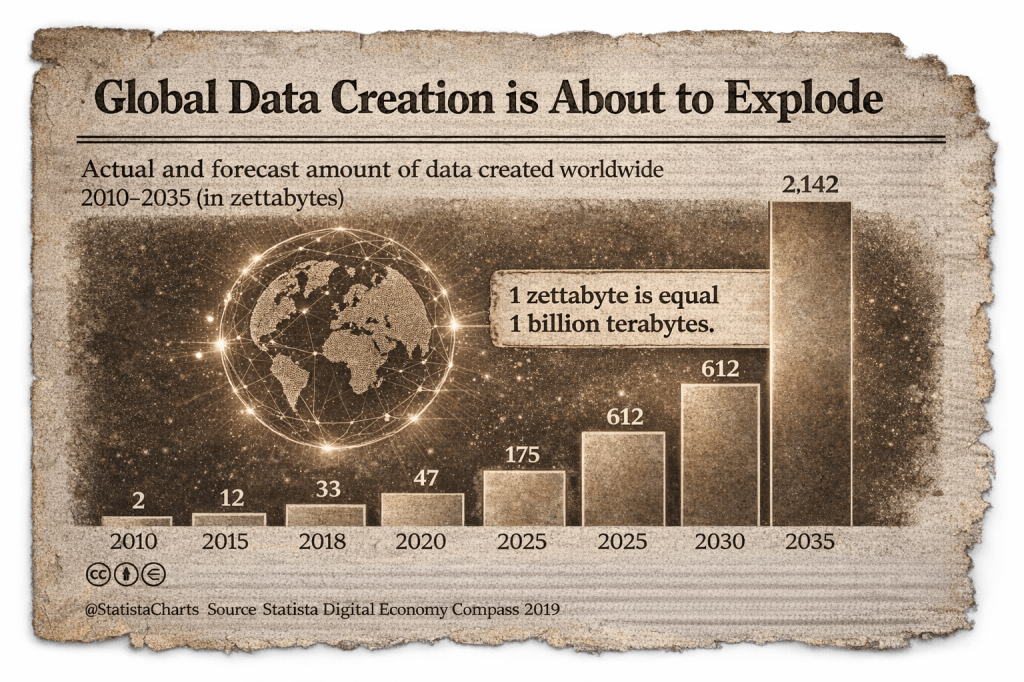
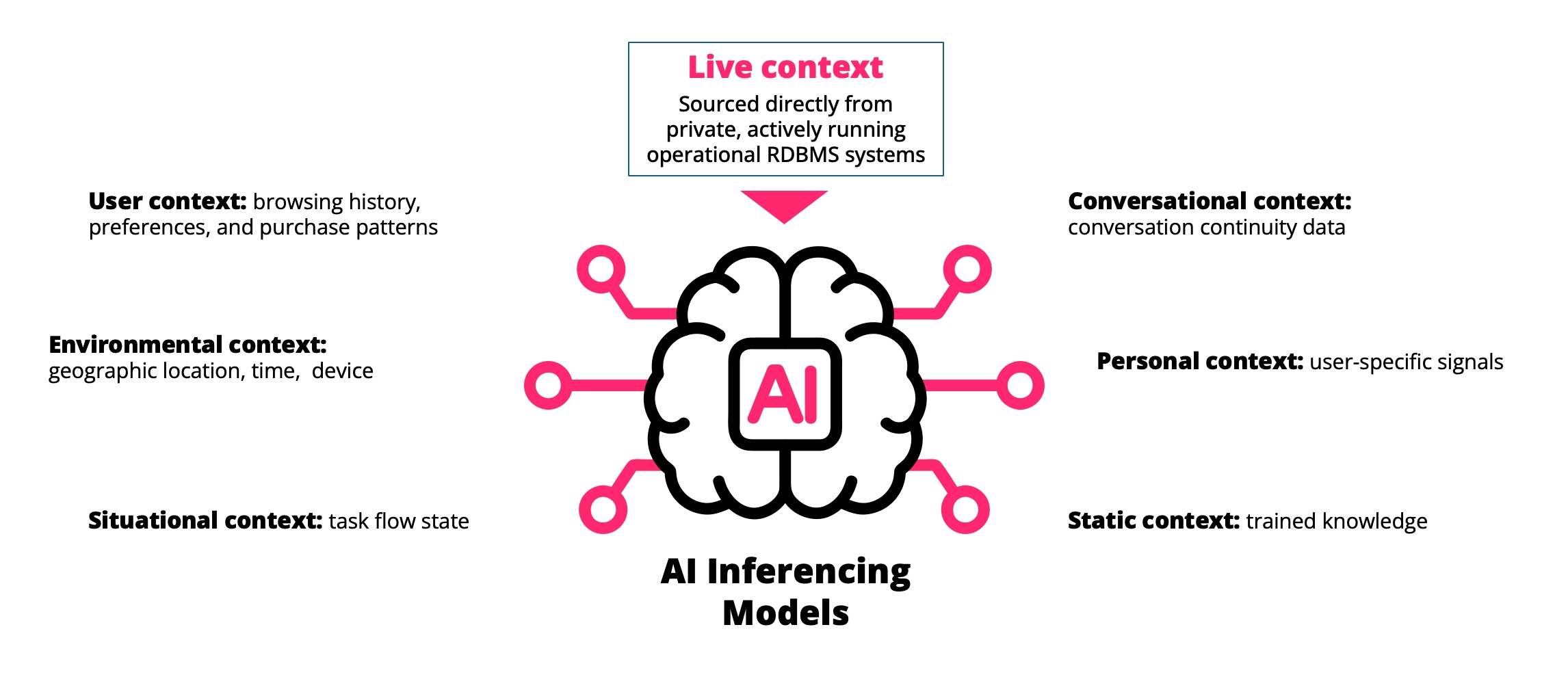
When engineers build infrastructure, they aim for stability. Systems must behave predictably under load. They must survive success as well as failure. Growth is assumed. If the system is successful, it will be stressed. The challenge is ensuring that growth does not destabilise the structure meant to support it.
Uniform Supply, Irregular Demand
The public cloud addresses this challenge through uniformity. Compute, storage and network capacity are delivered as standardised building blocks. Instance sizes are predefined. Performance characteristics are abstracted. Capacity can be replicated across availability zones and regions with remarkable consistency. This is the operational achievement of Amazon Web Services, Microsoft Azure and Google Cloud. Uniform supply enables hyperscale.
It is an extraordinary achievement. It is also deliberately impersonal.
Enterprise systems of record operate under different conditions. They reflect the behaviour of real customers and real businesses. Demand is rarely smooth. It clusters around product launches, reporting cycles, market opens, regulatory deadlines and seasonal peaks. A transactional database sits at the centre of this behaviour. It absorbs whatever the business generates.
It does not get to choose the shape of that demand.
Cloud infrastructure assumes that workloads can be distributed horizontally across uniform units. Systems of record often experience concentrated pressure at specific moments in time. This is not a flaw, although it can feel like one at 9:01 on Monday when performance dashboards are flashing red. It reflects the difference between uniform supply and irregular demand.
Statistical Guarantees, Deterministic Commit
The distinction becomes clearer when examining reliability. Cloud platforms express resilience statistically. Availability is measured in percentages. Durability in strings of nines. Performance in ranges and envelopes. At fleet scale, these models are extraordinarily effective.
Most of the time, that is enough.
Transactional systems optimise for a different property. When a transaction commits, it must commit correctly and in order. When state changes, it must change once. The authoritative copy of truth cannot be approximate. Modern database engines distribute storage and parallelise reads. But the semantics of correctness still converge at the transaction boundary. Correctness is deterministic even when the infrastructure beneath it is statistical.
Cloud platforms optimise for aggregate behaviour across fleets. Transactional systems optimise for the one transaction that must not be wrong. Both approaches are rational. They are aimed at different targets — and those targets matter most under stress.
Where the Models Converge
The economic model reinforces the distinction. Elasticity allows capacity to expand and contract in response to demand. Stateless services align naturally with this pattern. Horizontal replication tends to make cost proportional to usage.
That is the promise.
Systems of record often scale differently. Reducing latency, increasing memory and tightening the coupling between compute and data frequently precede horizontal distribution. Cloud providers offer very large instance types and strong performance isolation. It is entirely possible to achieve impressive stability and scale in this way — and not infrequently, equally impressive cloud bills.
However, as performance guarantees increase, elasticity typically narrows. Dedicated capacity replaces shared pools. Provisioned throughput replaces best-effort scheduling. Predictability rises. Flexibility declines. These are trade-offs rather than failures. They always have been.
For many years, architects could separate these optimisation philosophies. Operational systems preserved deterministic state transitions. Analytical platforms absorbed variability downstream.
AI Removes the Insulation
AI reduces that separation. Machine agents increasingly interact directly with live operational data rather than curated extracts. Inference engines that are inherently probabilistic now depend more directly on infrastructure expected to be exact. The probabilistic layer now relies on deterministic state in real-time.
This does not invalidate the cloud model, nor does it imply that systems of record do not belong there. It makes the architectural assumptions more visible. Uniform, statistical infrastructure interacts with non-uniform, deterministic state, and the optimisation choices at each layer become more tightly coupled.
Architects must therefore decide explicitly where determinism resides in their stack and what elasticity they are willing to trade to preserve it. Elasticity, isolation and correctness can coexist. But not infinitely, and never without cost.
Someone always pays for certainty.
The cloud is built on uniformity. Databases are built on authority. That authority carries operational consequence.
As AI tightens the feedback loop between them, trade-offs once hidden inside abstraction become explicit design decisions. And explicit design decisions are where responsibility ultimately resides.