8:53am on a Monday
I want to take you back roughly twenty years.
It is 8:53am on a Monday morning in central London and I am sitting at my desk staring at the screen. My coffee is untouched. My palms are sweating.
The ETL job is still running.
If that phrase means nothing to you, it was enough in the mid-2000s to strike fear into the heart of any production DBA. At the time I was the database lead for a SaaS platform serving customers across the UK, most of whom would start logging in from 9am.
The weekend ETL process (Extract, Transform, Load) pulled data out of the operational database, reshaped it and pushed it into the enterprise data warehouse. It ran every weekend and it was supposed to finish long before Monday morning.
It had not.
CPU pinned. Redo logs churning. User sessions beginning to queue.
In a few minutes customers would start calling support. Support would start calling me. And somewhere upstairs, the CEO would notice that his dashboard was still showing last week’s numbers.
I had two options. Let it run and hope it finished before the system buckled under real user traffic. Or kill it and spend the next hour watching rollback potentially take even longer, while guaranteeing that the warehouse would be stale until the following weekend.
How did we end up building systems where that was a normal Monday morning dilemma?
Why We Built the Wall
For the better part of two decades, the industry answered that question in one consistent way: keep analytics away from operational systems.
Transactional databases were designed to process orders, update accounts and record events predictably. Analytical workloads were different. They were heavy, exploratory and often poorly constrained. They scanned large portions of data, built aggregates, joined everything to everything and consumed CPU and I/O in bursts that were difficult to forecast.
Putting the two together in the same system was a recipe for contention.
So we separated them.
We built ETL pipelines. We built data warehouses. Later, we built data lakes and lakehouses. We introduced replication, change data capture and streaming. Each innovation was, in its own way, an attempt to preserve the integrity of the system of record while still making data available for analysis.
This was not fashion. It was defensive architecture.
The separation protected revenue-generating systems from analytical curiosity. It provided workload isolation. It gave operations teams a fighting chance of keeping Monday morning uneventful.
It Was Never Just About Performance
Enterprise environments rarely have a single system of record. A CRM system holds customer interactions. An ordering platform tracks transactions. Billing lives somewhere else. Supply chain somewhere else again.
The warehouse became not just a safety valve for analytics, but a unifying layer. It was the place where disparate operational systems could be reconciled into something coherent.
For years, this model worked.
Dashboards were allowed to be slightly stale. Reports could reflect yesterday’s state. Humans tolerate delay. In fact, they often prefer it. Analysis takes time, and decisions are rarely made in milliseconds.
The truce held because the consumer was human.
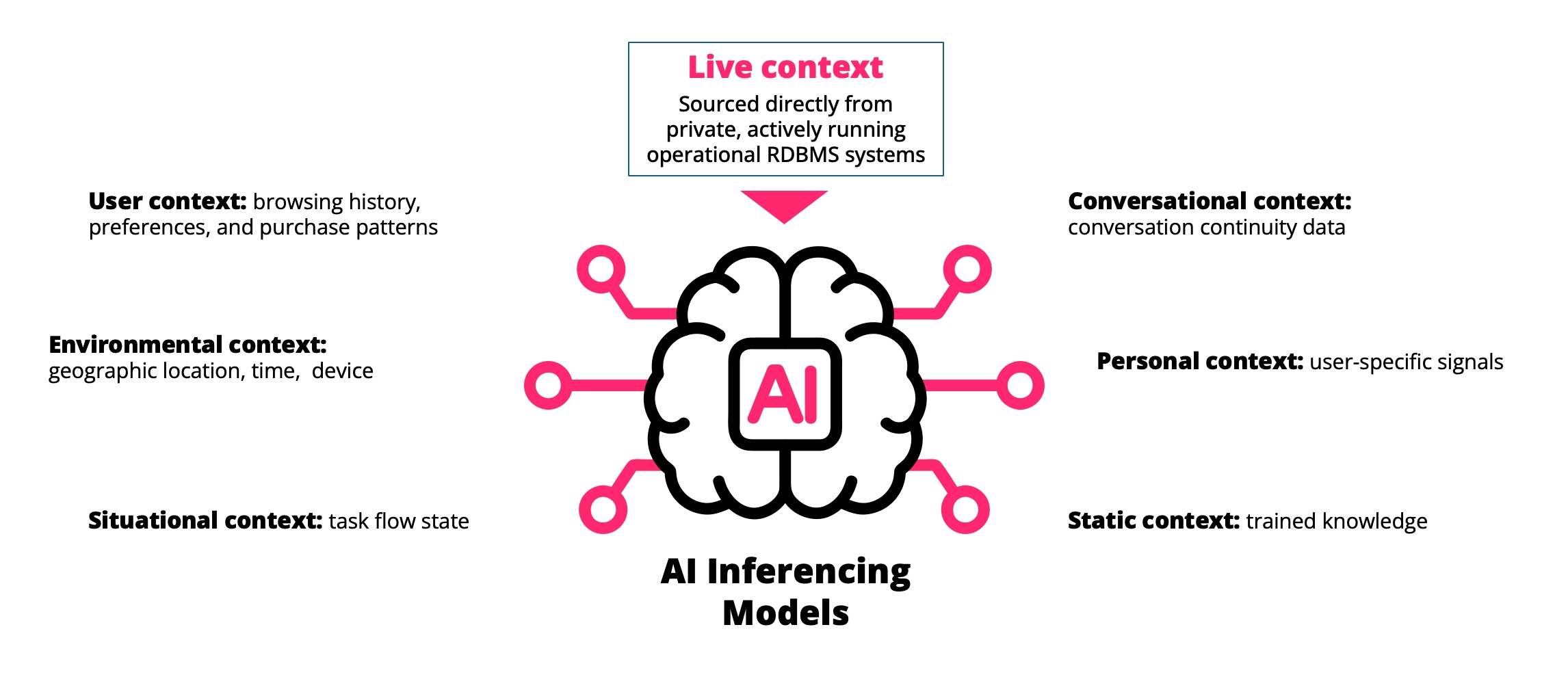
AI Changes the Consumer
AI agents change that.
An AI agent does not log in at 9am. It does not wait for a dashboard refresh. It does not tolerate yesterday’s numbers if it is expected to act on what is true right now.
Inference is not reporting. It is decision execution at machine speed.
If an agent is recommending a next action, approving a transaction, adjusting a price or triggering a workflow, the freshness of the underlying data becomes materially important. Close enough is no longer good enough. Staleness is no longer cosmetic. It alters outcomes.
The architectural assumption that analytics can safely run on a delayed copy of operational data begins to fracture.
This does not mean warehouses were a mistake. It does not mean lakehouses are obsolete. It does not mean streaming pipelines were misguided.
It means they were optimised for a different consumer.
For years, we optimised for human analysis. Now we are increasingly optimising for machine-driven action.
That is a different problem.
The Balance of Trade-Offs
For two decades, the answer was clear: keep them apart.
Protect the system of record. Move the data. Analyse it somewhere else. Accept a little delay in exchange for stability and control.
That architecture was forged in moments exactly like that Monday morning at 8:53am, CPU pinned, redo logs churning, business users about to log in.
AI does not invalidate that history. It simply changes the balance of trade-offs.
The truce between operational databases and analytics was built for a world where humans consumed insight.
We are now entering a world where machines consume state.
And that changes the conversation.