
Storage for DBAs: As a rule of thumb, pretty much any storage system can be characterised by three fundamental properties:
Latency is a measurement of delay in a system; so in the case of storage it is the time taken to respond to an I/O request. It’s a term which is frequently misused – more on this later – but when found in the context of a storage system’s data sheet it often means the average latency of a single I/O. Latency figures for disk are usually measured in milliseconds; for flash a more common unit of measurement would be microseconds.
IOPS (which stands for I/Os Per Second) represents the number of individual I/O operations taking place in a second. IOPS figures can be very useful, but only when you know a little bit about the nature of the I/O such as its size and randomicity. If you look at the data sheet for a storage product you will usually see a Max IOPS figure somewhere, with a footnote indicating the I/O size and nature.
Bandwidth (also variously known as throughput) is a measure of data volume over time – in other words, the amount of data that can be pushed or pulled through a system per second. Throughput figures are therefore usually given in units of MB/sec or GB/sec.
As the picture suggests, these properties are all related. It’s worth understanding how and why, because you will invariably need all three in the real world. It’s no good buying a storage system which can deliver massive numbers of IOPS, for example, if the latency will be terrible as a result.
The throughput is simply a product of the number of IOPS and the I/O size:
Throughput = IOPS x I/O size
So 2,048 IOPS with an 8k blocksize is (2,048 x 8k) = 16,384 kbytes/sec which is a throughput of 16MB/sec.
The latency is also related, although not in such a strict mathematical sense. Simply put, the latency of a storage system will rise as it gets busier. We can measure how busy the system is by looking at either the IOPS or Throughput figures, but throughput unnecessarily introduces the variable of block size so let’s stick with IOPS. We can therefore say that the latency is proportional to the IOPS:
Latency ∝ IOPS
I like the mathematical symbol in that last line because it makes me feel like I’m writing something intelligent, but to be honest it’s not really accurate. The proportional (∝) symbol suggests a direct relationship, but actually the latency of a system usually increases exponentially as it nears saturation point.
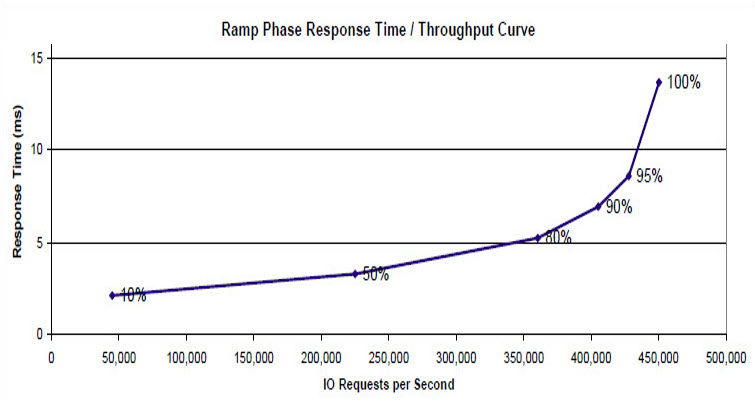
We can see this if we plot a graph of latency versus IOPS – a common way of visualising performance characteristics in the storage world. The graph on the right shows the SPC benchmark results for an HP 3PAR disk system (submitted in 2011). See how the response time seems to hit a wall of maximum IOPS? Beyond this point, latency increases rapidly without the number of IOPS increasing. Even though there are only six data points on the graph it’s pretty easy to visualise where the limit of performance for this particular system is.
I said earlier that the term Latency is frequently misused – and just to prove it I misused it myself in the last paragraph. The SPC performance graph is actually plotting response time and not latency. These two terms, along with variations of the phrase I/O wait time, are often used interchangeably when they perhaps should not be.
According to Wikipedia, “Latency is a measure of time delay experienced in a system“. If your database needs, for example, to read a block from disk then that action requires a certain amount of time. The time taken for the action to complete is the response time. If your user session is subsequently waiting for that I/O before it can continue (a blocking wait) then it experiences I/O wait time which Oracle will chalk up to one of the regular wait events such as db file sequential read.
The latency is the amount of time taken until the device is ready to start reading the block, i.e not including the time taken to complete the read. In the disk world this includes things like the seek time (moving the actuator arm to the correct track) and the rotational latency (spinning the platter to the correct sector), both of which are mechanical processes (and therefore slow).
When I first began working for a storage vendor I found the intricacies of the terminology confusing – I suppose it’s no different to people entering the database world for the first time. I began to realise that there is often a language barrier in I.T. as people with different technical specialties use different vocabularies to describe the same underlying phenomena. For example, a storage person might say that the array is experiencing “high latency” while the database admin says that there is “high User I/O wait time“. The OS admin might look at the server statistics and comment on the “high levels of IOWAIT“, yet the poor user trying to use the application is only able to describe it as “slow“.
At the end of the day, it’s the application and its users that matter most, since without them there would be no need for the infrastructure. So with that in mind, let’s finish off this post by attempting to translate the terms above into the language of applications.
Translating Storage Into Application
Earlier we defined the three fundamental characteristics of storage. Now let’s attempt to translate them into the language of applications:

Latency is about application acceleration. If you are looking to improve user experience, if you want screens on your ERP system to refresh quicker, if you want release notes to come out of the warehouse printer faster… latency is critical. It is extremely important for highly transactional (OLTP) applications which require fast response times. Examples include call centre systems, CRM, trading, e-Business etc where real-time data is critical and the high latency of spinning disk has a direct negative impact on revenue.
IOPS is for application scalability. IOPS are required for scaling applications and increasing the workload, which most commonly means one of three things: in the OLTP space, increasing the number of concurrent users; in the data warehouse space increasing the parallelism of batch processes, or in the consolidation / virtualisation space increasing the number of database instances located on a single physical platform (i.e. the density). This last example is becoming ever more important as more and more enterprises consolidate their database estates to save on operational and licensing costs.
Bandwidth / Throughput is effectively the amount of data you can push or pull through your system. Obviously that makes it a critical requirement for batch jobs or datawarehouse-type workloads where massive amounts of data need to be processed in order to aggregate and report, or identify trends. Increased bandwidth allows for batch processes to complete in reduced amounts of time or for Extract Transform Load (ETL) jobs to run faster. And every DBA that ever lived at some point had to deal with a batch process that was taking longer and longer until it started to overrun the window in which it was designed to fit…
Finally, a warning. As with any language there are subtleties and nuances which get lost in translation. The above “translation” is just a rough guide… the real message is to remember that I/O is driven by applications. Data sheets tell you the maximum performance of a product in ideal conditions, but the reality is that your applications are unique to your organisation so only you will know what they need. If you can understand what your I/O patterns look like using the three terms above, you are halfway to knowing what the best storage solution is for you…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

HI,
even if i did not comment your very first post about storage i wanted to tell you that i found your “It’s all about balance” very, very interesting and very inovative. I’ve never thought about cpu/memory/storage this way, and it’s probably the best introduction i’ve ever read about the complex storage performance topic.
Now regarding this new post which is also very interesting i have a few comments / questions :
when you comment the SPC benchmark, you speak about I/Ops. However i find this a bit confusing : one could think in the first place that you’re speaking about the number of I/Ops the disk array can deliver, when actually it’s about the number of I/Ops Requests (as it’s written on the graph). You might also (but maybe it’s out of topic) mention that as opposed to CPU, Disks can be assimilated to a bunch of queues (when multi cpus can be assimilated to one single queue, what ever the number of core is).
Thank you for your kind feedback.
Regarding the SPC results, when a vendor produces a datasheet they will usually list the maximum IOPS that the product can deliver (normally with a footnote indicating the IO size). They might also describe the average latency (perhaps with another footnote). You can be sure that the max IOPS figure will be using whatever blocksize gives the best result – normally the physical blocksize of the storage media (e.g. 512 bytes for legacy disks, 4k for advanced format devices). The latency figures will probably be from a different number of IOPS. Essentially, the data sheet shows only the best numbers.
The SPC benchmark is designed to give more detail in that it allows you to plot a graph of IOPS versus latency so you can see how the two characteristic are related as load increases. This is useful, although for database purposes not as useful as actually driving the I/O through Oracle (which is what a tool like SLOB allows).
You are absolutely right about the queueing, but I felt that was getting into too much detail for this post.
Questions :
1) Regarding the number of I/Ops, :
How this number is evolving when the I/O size is larger ?
When you speak about I/O size, do we speak about a larger I/O for which blocks would be contiguous on disks ?
2) Something you have not talked about and i’m dying to ask for : we use to speak about random I/Os and sequential I/Os. The question might sound like silly, but from which I/O size do we consider the I/O is not random anymore but sequential ?
1/ It’s quite simple. If a flash array can perform a maximum of 1 million IOPS at a block size of 4k, then at 8k it is going to be able to perform approximately 500k IOPS maximum. This is because flash arrays have an underlying physical block size which cannot be changed. For Violin it is 4k, as it is for most modern flash products. However, there are some exceptions in the flash world who use 512 bytes as a block size (and even seek to portray that as a benefit). The reality is that every 8k IO you perform to flash is actually 2 x 4k IOs on the back end. Thus the 500k IOPS at 8k blocksize is really causing 1 million IOPS with a 4k blocksize on the array.
2/ Ok well it’s interesting you ask that. I have a number of articles planned for this blog series and the next one was on random versus sequential IO – which is why I didn’t mention it here (I am aware my posts are already too long). However, today I looked at the list of topics and decided that it didn’t make sense to cover random vs sequential until I’d covered the later post of Understanding Disk Technology. After your comment I may have to reconsider.
I’ll give you a sneak preview though. In flash there really isn’t such a concept as sequential I/O. It’s only a disk thing. So the answer is simple… but the implications are long lasting…
Thanks for clarifying the impact of I/Osize for a flashdisk array. however my question was much more related to non flash diskarray : During my own experience, when trying to figure out if disk response time was acceptable, i have allway applied a rule of thumb (which might be wrong) and which was stating that over ~10ms there was too much queuing for I/Os. If we consider that 10ms is the service time, so over 10ms means we have queuing for I/Os and thus reponse time is increasing RT=S[ervice]T[time]+Q[queuing]T[time].
Now, with a 10ms of service time this would mean the disk can deliver 1/0.01=100I/Os per second. The question i have is the following : If the I/O size is increasing, is it really impacting the number of I/Os the disk can deliver ? I realize that i have to make a difference between the Number of I/Os requested (as well as their size) from an application perspective and the number of I/Os services at the disk level : Let’s say i have an application requesting I/Os which are 1MBytes size. If the blocks i’m requesting are contiguous on disk then I will experience the service time to move the disk read head, but then since blocks are contiguous on disk, then I/Os are serviced without these 10ms required to move the disk read head (I know i’m over simplifying what makes these 10ms).
Questions : when blocks are contiguous, are each 512/4k block delivered considered as a single I/O from a disk perspective ? or is the entire 1MB I/O requested from an application perspective considered as a single I/O from a disk perspective ?
I guess that if from a disk perspective we consider that any single 521/4K block requested being serviced as an I/O then it’s easy to understand that in case of sequential reads, i should be able to deliver much more I/Os.
Am i right with such statements ?
Thanks again for your answers.
(I realize that i might be asking questions we are to be addressed later on other blog posts).
Ah ok, you are talking about disk. But it’s important to understand that between the application or database and the underlying physical hardware (disk or flash) there are many other layers, such as the operating system’s block layer and any storage fabric (e.g. fibre-channel). All of these layers can have a say in what happens.
At a basic level, an I/O is a single input/output operation – of any size, although the size must be between minimum and maximum limits. In later Linux kernels (2.6.32 and above) you can see these limits easily by looking in the SYSFS filesystem’s queue directory:
http://www.mjmwired.net/kernel/Documentation/block/queue-sysfs.txt
In the case of disk, if you are reading contiguous blocks then they can be read in a single I/O up to the maximum size allowed by the block layer (shown in /sys/block//queue/max_sectors_kb. This limit can be increased up to the maximum I/O size allowed by the hardware (shown in /sys/block//queue/max_hw_sectors_kb).
However, the fact that the blocks you are requesting are contiguous is not enough on its own to result in a sequential I/O. If the application is making multiple single-block read requests for contiguous blocks then they will be treated as separate I/Os. This is why, for disk, you have an entity within the Operating System called the I/O Scheduler. It’s job is to look at I/O requests and see if they can be reordered in order to allow merges, i.e. turning multiple single I/O requests into smaller numbers of sequential requests (thus reducing the number of IOPS). This is necessary for disk because it saves the impact of disk head seek times and rotational latency.
In the case of flash there is no such concept as “contiguous blocks” so it’s not necessary to use an I/O Scheduler to perform merges.
There’s more to this topic but if I write it all here I’ll never end up writing the next blog post 🙂
Absolutly clear ! Thanks for the provided details. very helpfull to understand 🙂
I might have more question on this new post but i have to read it again and again, because as first post, the way you’re explaining storage brings to me lots of new perspectives i had not thought about before. I’s obvious you’ve been swimming in this field for a while, and you have very good ability to explain this topic which is not that much covered in books.
Thanks again for this incredible stuff !
Olivier
Thanks! For years I’ve read the blogs of real experts like Kevin, Tanel and Jonathan Lewis and felt that I would never be able to contribute to the Oracle world in the same way. Although the stuff I write is nowhere near the league of these guys, I’m glad to have something to write about that helps the Oracle community even a little bit.
Keep going on, the quality of your posts is frankly much appreciated. Now i understand you might also be very busy in your own job. Anyway, this means much more time to read your stuff and thinking about the good questions to ask 🙂
Hi,
I am looking for data on IOPS and bandwidth provided by optical-media. I am doing it to do the cost-benefit analysis of using hard disks, SSD, optical-media, and tape. I see that while bandwidth for tape, hard disks, and SSD is defined in terms of MB/s, for optical-media, it is defined in Mb/s. I found that for optical-media bandwidth is approximately 60 Mb/s which would be close to 8MB/s. This seems quite low. However, when I use CD or DVD in my laptop they don’t run that slow.
I could not find any data on Input output operations provided by optical-media. Do you guys have any numbers on that?
Hi… that’s an interesting idea. Although optical media is generally read-only, or at the very least is a Write Once Read Many format. That makes it kind of hard to compare with disk and SSD. The other difference with optical media is that it uses a Constant Linear Velocity (i.e. the rotational velocity changes to ensure that the head moves over the disc at the same linear speed. This is as opposed to hard drives, which use a Constant Angular Velocity model, so that the number of sectors passing the head at any given time is greater when the head is further towards the outside of the platter. The use of CLV in optical media is not going to help any quest for IOPS, since in addition to the rotational latency and seek time for the head to move there may also be a delay in waiting for the drive motor to reach the correct speed.
At least, that’s what occurs to me… but let me be honest: I don’t know much about optical media at all. From what I can see the definition of a 1x speed CD-ROM is 150 KiB/sec, which means a modern 56x drive would read at around 8.2MiB/sec. That agrees with your calculation – although we may be working from the same source data 🙂