Not every database benefits from flash storage – knowing when it matters requires understanding how much I/O your workload generates, how random it is and how much latency is already costing you.
Does My Database Need Flash?

Not every database benefits from flash storage – knowing when it matters requires understanding how much I/O your workload generates, how random it is and how much latency is already costing you.

Disk I/O forces a choice between random and sequential access – and that choice defines whether latency compounds or disappears. Flash makes the distinction irrelevant.
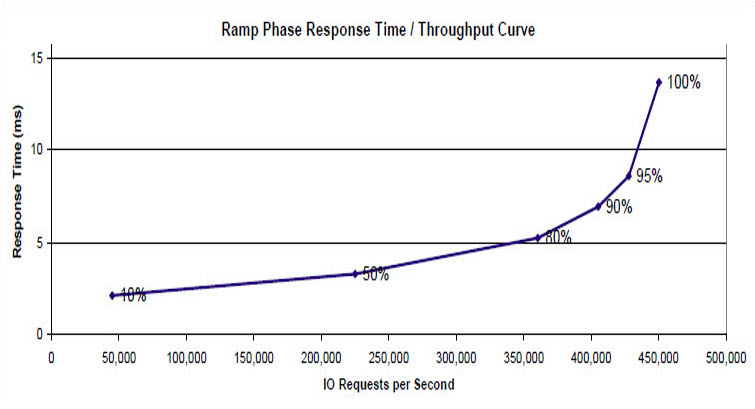
Latency, IOPS and bandwidth are the three properties that define any storage system – understanding how they relate to each other is the first step to knowing what your database actually needs.

Database performance problems are rarely solved by faster CPUs alone – the real issue is imbalance between resources, and disk latency is the silent bottleneck that flash storage changes.

DBAs and storage people speak different languages – this series bridges the divide, translating storage concepts into terms that make sense from a database perspective.
