
Guest Post
This is another guest post from my buddy Nate Fuzi, who performs the same role as me for Violin but is based in the US instead of EMEA. Because he’s an American, Nate believes that “football” is played using your hands and that the ball is actually egg-shaped. This is of course ridiculous, because as the entire rest of the world knows, this is football whereas the game Nate is thinking of is actually called “HandEgg”. Now that we’ve cleared that up, over to you, Nate:
Lately, I’ve been running into much confusion around Oracle’s direct path IO functionality (11g+) and, unusually, not all of that confusion is my own. There is a perplexing lack of literature and experimentation with direct path IO on the Internet today. Seriously, I’ve looked. I decided I needed to better understand this event and its timing in order to properly extend suggestions to customers. I set about trying to prove some things I thought I knew, and I managed to confirm several suspicions but also surprised myself with some unexpected results. I’d like to share these in hopes of clarifying this event for everyone in practical terms.
Direct Path IO Background
To set the stage a bit, at the highest level, Oracle created the direct path IO event to describe an IO executed by an Oracle process that reads into (or writes from) the process global area (think of this as the session’s private memory) directly from (to) storage, bypassing the Oracle buffer cache. The rationale is this: full table scans of large tables into the buffer cache consume a lot of space, pushing out likely useful buffers in favor of buffers unlikely to be needed again in the near future. Reading directly into the process global area instead of the shared global area keeps full table scans from polluting the buffer cache and diminishing its overall effectiveness. Since the direct path IO is used for full scanning large objects, it looks to the database’s DB_FILE_MULTIBLOCK_READ_COUNT (henceforth referred to as DBMRC) setting for guidance on the size of IO calls to issue.
Makes sense. But what’s been confusing me is the apparently inconsistent performance of direct path reads and writes, even against Violin’s all-flash arrays. With random and other multi-block IO events showing very low, consistent performance, direct path reads can still be all over the board. How is that? Is it truly impacting performance? How can I make it better, or should I even try? After seeing this at a number of customer installations, I decided to run some tests on a smallish lab server attached to a single Violin array.
The Setup
I have a test database with a number of tables almost exactly 125GB in size full of randomized data. Full-scanning one of these tables via “select count(*)” was plenty to exercise the direct path read repeatedly, varying parallelism and DBMRC. My goal was to see the effect of these settings on both elapsed time and perceived latency. With an 8K database block size (RHEL 6.3, Oracle 12.1.0.1, ASM), I ran the test with DBMRC set to 4, then 8, 16, and finally 128. I ran each test with no parallelism, then with “parallel 16” hinted. So what did I see?
Test Results
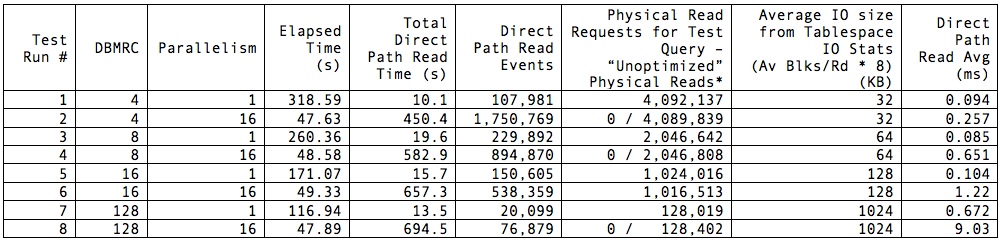
Note that elapsed times represent the time my query returned to the SQL*Plus prompt with the “set timing on” directive applied to my session and are not 100% representative of time spent on the database but are close enough for my purposes. Total direct path read (DPR) time was pulled from the respective AWR report after execution finished. I asterisked the Physical Read Requests column because some of the reports showed 0 physical reads for the test SQL, while it was clear from the total physical reads that my read operation was the only possible culprit; therefore I felt justified in attributing that total (minus a few here and there from the AWR snapshotting process) to the test SQL. Note also that the best elapsed time was achieved with the lowest DBMRC and parallel 16. Worst time by far was also obtained with DBMRC set to 4 but without parallelism—although it accumulated the least amount of wait time on DPR. In general, throwing more cores at the problem improved performance hugely; not surprising, but noteworthy. We know that flash does not benefit from multi-block IO as a rule: at the lowest level, every IO is effectively a random IO, and larger blocks / groups of blocks are fetched independently, assembled, and returned to the caller as a single unit. However, there is a definite overhead in issuing IO requests, waiting for the calls to return, and consuming the requested data. This is evidenced by the high elapsed time for the single-threaded run with DBMRC set to 4: the least amount of reported IO wait time still contributed to the longest overall elapsed time.
So what do these values tell us? For one thing, parallelism is your friend. One core performing a FTS just isn’t going to get the job done nearly as quickly as multiple cores. Also, parallelism vastly trumps DBMRC as a tool for improving performance on flash when CPU resources are available. Performance between parallel processing runs was within 2%, no matter what the DBMRC setting. This I expected, having come into the testing with the assumption that DBMRC was irrelevant when working with flash. I was surprised at the exceedingly high elapsed time with the single-threaded query using small DBMRC. I would expect that to be higher than the others, but not nearly 3X longer than the single-threaded run with DBMRC at 128.
These revelations are mildly interesting, but what I find much more curious is the difference in reported DPR latency. Certainly, a highly parallel execution can accumulate more database time than wall clock time for any event. But we can tell from the elapsed times that, when we’re not starving the database for parallelism, DBMRC is practically meaningless when applied to flash. Yet the calculation of the average latency of the event is mysterious in that 1) 16 threads operating with DBMRC of 128 experiences roughly 4X the number of waits the single-threaded execution performs; 2) it does so apparently at about 13X the average latency of the single-threaded run; and 3) it racks up about 51X the amount of total DPR wait time.
What’s worse is that DPR stats are very strangely represented in the Tablespace IO stats section of the report. Here’s the snippet from test run #2:
Av Av Av 1-bk Av 1-bk Writes Buffer Av Buf Tablespace Reads Rds/s Rd(ms) Blks/Rd Rds/s Rd(ms) Writes avg/s Waits Wt(ms) ---------- ------- ------- ------- ------- ------- ------- ------- ------- -------- ------- DEMO 4.1E+06 49,395 0.0 4.0 2 0.0 0 0 0 0.0
We have to cut Oracle some slack on the Av Rds/s value here because it’s now averaging over the time it took me to start the test after my initial snapshot, then realize the test was done and execute another AWR snapshot to end the reporting period. Fine. But an average read time of 0.0ms?! Clearly, Oracle is recording some number of reads, but it’s not reporting timing on them at all in this section of the report. We have to look to the SQL Ordered by Physical Reads (Unoptimized) section of the report to confirm it’s actually doing a relevant number of IO requests:
-> Total Physical Read Requests: 4,092,389
-> Captured SQL account for 0.0% of Total
-> Total UnOptimized Read Requests: 4,092,389
-> Captured SQL account for 0.0% of Total
-> Total Optimized Read Requests: 1
-> Captured SQL account for 0.0% of Total
[some lines removed]
UnOptimized Physical UnOptimized
Read Reqs Read Reqs Executions Reqs per Exe %Opt %Total SQL Id
----------- ----------- ---------- ------------ ------ ------ -------------
0 0 1 0.0 N/A 0.0 4kpvpt49hm3nf
Module: SQL*Plus
PDB: DEMO
select /*+ parallel 16 */ count(*) from demo.length100_1
Oh, wait. Oracle doesn’t credit my query with any physical read requests. I have to look at the total just above in the report, and see that only the AWR snapshot performed any other IO on the system, and subtract that from the total. Sigh. At least ~4.1M reads at 32KB comes close to 125GB.
So what gives, Oracle? I’ve read some Oracle notes and other blogs on the subject of DPR, and they suggest the wait event is not necessarily triggered when the IO call is initially issued, but instead when the session decides it needs all outstanding DPR IOs it has issued to complete before moving on—or it fills up all its “slots” and has to wait for those to free up. Thus the under-reporting of the actual number of DPR waits and the artificially high wait time for each of those waits: fewer waits, along with potentially many IO requests outstanding when the wait is triggered and timing starts. But nowhere in all of this is there a set of numbers that I can trust to accurately describe my DPR performance. The fact that DPR IO is completely left out of tablespace timings is seriously troubling: we trust these stats to determine “hot” tablespaces and under-performing mount points. This throws all kinds of doubt into the mix.
What can I say about Oracle’s DPR at this point? While it works just fine and serves its purpose, the instrumentation appears to be lacking, even in Oracle 12.1. After this testing, I feel even more confident telling customers to ignore the latency reported for this event—at least for now. And I’ve confirmed my belief that, with any sort of parallelism enabled on your database, DBMRC is largely irrelevant for flash storage and only adds a mystery factor to reported latencies. Yes, setting this to a low value will affect costing of FTS vs. index access, so you should verify that plans currently employing FTS that you want to remain that way still do. This is easy enough with an alter session and explain plan. With that, Oracle, the ball is in your court: please define your terms, fix your instrumentation around DPR, or tell customers to stop worrying about DPR latencies. Meanwhile, I’m going to advise people who are otherwise happy with their performance but want better latency numbers in their reports to set DBMRC lower and get on with their lives.

Thanks for humoring me with this post, sir. Maybe some of your readers will wade through it and offer insights on the subject.
BTW, just completed my fantasy HandEgg draft last night and am stoked for the season to begin!
Haha… dude you crack me up with your funny spelling and use of the Queen’s English.
Thanks as always for your great contributions to my humble site, amigo.