
One of the important characteristics of flash memory is wear. We know from previous articles in this series that flash packages consist of dies, which contain planes, which contain blocks, which in turn contain pages. We also know that these pages contain individual cells which store the bits of data… but to understand what wear is we need to look a little bit closer at those cells, where we will find something called a floating gate transistor.
Now don’t run away. Electronics might not be your thing, but I’m won’t be getting too deep. [After all, I once attempted degree-level education in Electronic Engineering but had to move to another course because I kept burning my fingers on the soldering irons during practical laboratory sessions…] If you really don’t want to think about transistors you can just skip to the section called Wear, or ignore this blog post entirely and spend a few minutes looking at picture of cats instead.
Field Effect Transistors
If you are reading this blog on a computer or a phone (and how else could you be reading it?) you owe a debt of gratitude to a humble device called the metal oxide semiconductor field effect transistor, or MOSFET. These tiny devices revolutionised the world and are considered by some to be the most important invention of the 20th century.
They therefore deserve to be explained in a serious and respectful manner, but sadly I don’t have time for that so I’m going to resort to one of my silly analogies. Again.
Imagine you have a house full of students, which we’ll call the source. Two doors down the road you have a nightclub full of free alcohol, which we’ll call the drain. However, it’s freezing cold outside and the students won’t venture out of the door, meaning there is no flow of students from source to drain. Now let’s set up a banging sound system behind the wall of the property in between. If we play music loud enough through the wall then we can excite the students into action, causing them to run down the road and enter the nightclub, which creates the flow. The loud music (which we’re going to call the gate) is the stimulus which causes this flow, essentially acting as a switch, while the volume of the music which first drives the students into action is called the threshold. The beauty of this design is that we can control the flow of students from behind the wall, therefore avoiding having to come into direct contact with them. Phew.
I really cannot tell you how bad that analogy is, but I’m afraid it’s only going to get worse later on. If you don’t know how a transistor works I implore you to watch this short video from the excellent folk at Veritasium, which describes it far better than I ever intend to.
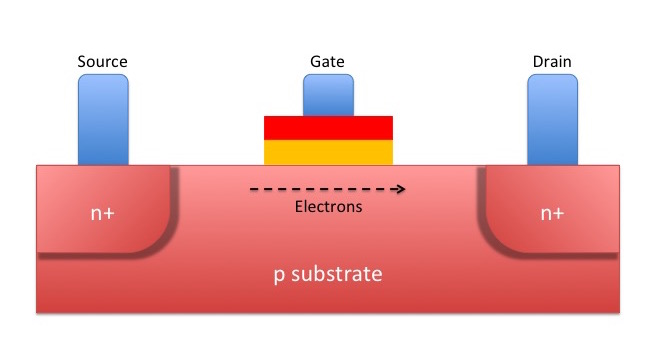
In a MOSFET, electrons (students!) can be allowed to flow from the source terminal to the drain terminal by the application of charge to the gate terminal. This charge creates an electric field which alters the behaviour of the silicon layers (the pinkish parts of the diagram) and thus controls the flow. The important bit here is the yellow rectangle which represents an insulating layer (commonly known as the oxide layer). This means the gate is never physically connected to either the source or drain terminals – and you’ll see why this is important as we turn our attention now to something called the floating grate transistor, or FGMOS.
There are many things I haven’t explained in that clumsy analogy, but this is not an electronics blog. Of specific interest is the way that the two types of silicon (n and p) are doped in order to create free electrons and electron holes. Seriously, watch the video. If you haven’t ever learnt how a semiconductor works and my student party analogy is the nearest you get, it would be a crime. Although that’s not going to stop me from using it again in the next section…
Floating Gate Transistors
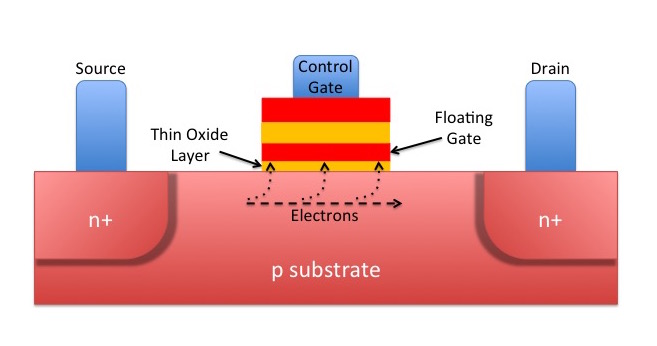
The diagram on the right (labelled “FGMOS”) is of a Floating Gate MOSFET, which is essentially what you will find in a flash memory cell. If you play spot the difference with the previous diagram above (the one labelled “MOSFET”) you’ll see that there are now two gates, one above the yellow oxide layer as before but the other entirely surrounded by it. This second gate is known as the floating gate because it is completely electrically isolated.
Notice also that the oxide layer beneath the floating gate is deliberately thinner than that above it in the diagram. Now, back to my analogy…

The students are still there, as is the nightclub. The property in between is still there, but this time we have replaced the brick wall at the front with one of those sets of PVC strip curtains that you sometimes find covering the doors of factories, or butchers shops to keep insects out (or even lining the edge of the cold aisle in a data centre). Inside, we’ll put some comfy chairs and maybe a beer fridge. This is now our floating gate party room and the PVC strips are our thinner section of oxide layer.
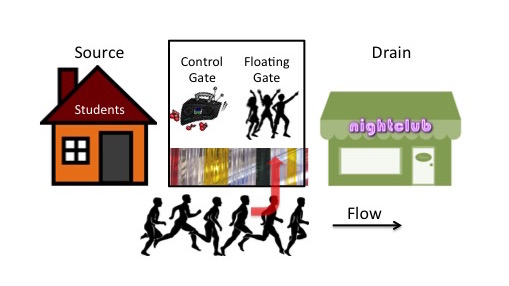
As we now play the music loud enough to exceed the threshold, the excited students will run up the road towards the bar as before, but this time – with enough excitement – some of them will pass through the divider into our floating gate room and remain there, thus trapping electrons (sorry, I mean students) on the floating gate. Meanwhile, as the floating gate room fills up with people, the sound of the music becomes more muffled which slows down the flow of students in the road outside. To put it another way, the volume threshold at which stimulation will occur rises if there are students (sorry, I mean electrons) on the floating gate.
In a FGMOS, if a high charge is applied to the control gate in the same manner as with a MOSFET, electrons flowing from source to drain can get excited and “jump” through the oxide layer into the floating gate, increasing its retained charge. This is the program operation we have talked about so many times before: the floating gate is the “bucket of electrons” from my previous posts (a classic case of mixed metaphors). To erase the charge stored on the floating gate, a high voltage is applied across the source and drain while a negative voltage is applied to the control gate, causing the retained electrons to “jump” back off the floating gate (through the oxide layer). I’m putting the word “jump” in inverted commas there because it’s slightly more complicated and usually involves a process called Fowler–Nordheim tunnelling. I’ll explain everything I understand about that in the next paragraph.
[This paragraph intentionally left blank]
Yeah, it’s complicated, it involves quantum mechanics and it’s way over my head. I’m just taking it for granted that it works.
Read Operations
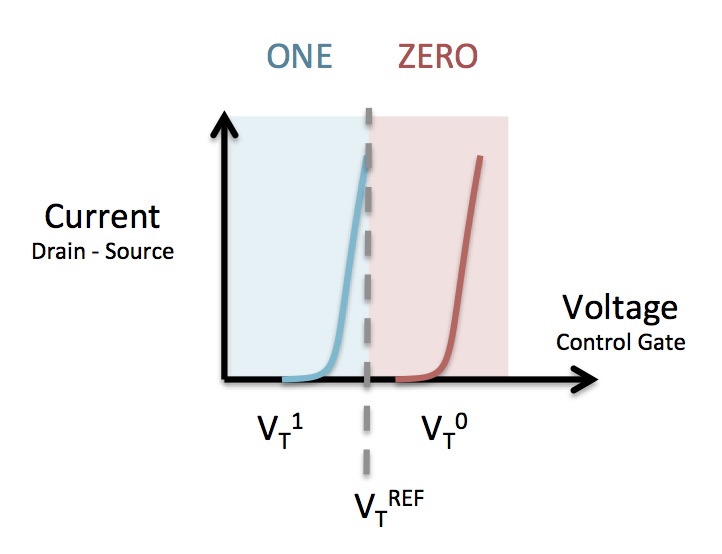
Now that we have methods for programming and erasing we just need a way of testing the value stored: a read operation. When we were talking about the MOSFET in the previous section we could control the flow of charge (which I had better start calling current) between source and drain by varying the voltage applied to the gate.
In the FGMOS this can be turned around so that by measuring the current we can determine the voltage on the floating gate, because electrons trapped on the floating gate cause the threshold we’ve previously mentioned to move. By applying a certain voltage (VtREF in the diagram on the right) across the source and drain and then testing the current we can determine if the voltage on the gate is above or below a specific point, called the read point.
So, if we play music at a certain threshold volume when the floating gate party room is empty, the sound travels far enough to stimulate a flow of students to the nightclub. But if the room is full (the floating gate contains charge) this specific volume will not stimulate a flow. Instead, it will require a louder threshold volume to get the students out of bed. And I think it’s time to abandon the student analogy now… let us never speak of it again.
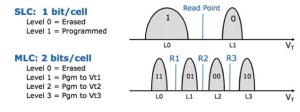
If you remember, flash comes in different forms: SLC, MLC and TLC. So why are MLC reads slower than SLC, with TLC even slower still? Well, because SLC contains only one bit of data (two possible states: a zero or one), we only need to test one threshold voltage, i.e. SLC only has one read point. But for MLC, where there are two bits (and therefore four possible states), there are three read points… while for TLC there are even more.
Remember the bucket full of electrons analogy? When you test the SLC bucket to see if it’s above or below 50% full, the answer will tell you whether the stored value is a zero or a one. But for the MLC bucket, the answer to that test isn’t enough: based on the first answer you then need to perform a second test to see if the bucket is above or below 25% / 75% [delete as appropriate] full. All this additional testing takes time, which is why SLC reads are faster than MLC reads, which in turn are faster than TLC reads.
But what about the wear?
Flash Wear

Finally I’m getting to the point. Remember the PVC strip curtains, like the ones in the main picture at the top of this post? What do you think happens to them as all those excited students (sorry) hurtle through them? They get damaged. In a FGMOS the oxide layer which isolates the floating gate from the silicon substrate is designed to be thin enough to allow quantum tunnelling of electrons when a high enough charge is applied, but this process gradually damages the layer. Reads are not a problem because only lower voltages are used and no electron tunnelling takes place. But program and erase operations are a different story, which is why wear is measured by the number of program/erase cycles. As the layer gets more damaged, the isolation of the floating gate is increasingly affected and the probability of stored charge leaking out will increase.
For SLC this is less of an issue, because during a read we only need to measure at one read point – so there is a lot of room for error either side of the threshold. But for MLC, with three read points, we need to be much more exact. Thus the wear caused by using SLC, MLC and TLC isn’t really very different, it’s simply that the tolerances for error are much finer with the increased bit counts of MLC and TLC.
At some point, the oxide layer for a FGMOS will become sufficiently degraded so that it can no longer store charge properly on the floating gate. We won’t know about this until it happens, but at some point a read from the cell will no longer be trustworthy. And clearly that’s a problem for data storage, which is why (just like disk) flash stores error correction codes (ECC) alongside user data to ensure that incorrect information is spotted and dealt with while any underlying pages are marked as unusable – all without impacting users.
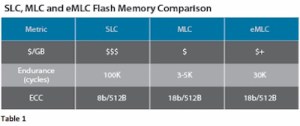
A final point to consider is that there is a (more expensive) form of MLC known as eMLC (the e stands for enterprise, with “normal” MLC then sometimes referred to as consumer or cMLC). The only difference between eMLC and the standard cMLC we have discussed in the past is that program and erase operations are “slowed down” for eMLC in order to cause less damage to the oxide layer. This gives slightly reduced performance but also significantly reduces wear, allowing up to 10x more P/E cycles. Opinion is divided on whether this is actually a worthwhile investment (not for me though, I think it’s a waste of money in the majority of cases).
Hot News
That’s the end of this post – and as usual I’ve committed two of my three regular blogging sins: writing too much, using silly analogies and finishing on a terrible pun. Time to complete the trio:
Some flash companies have been experimenting with methods of refreshing the lifetime of flash, with one avenue of exploration focussed on providing a short burst of heat to repair the damage to the oxide layer. It has been claimed that flash treated this way can sustain over 100 million P/E cycles with no noticeable degradation. If that is really the case – and this technology can be put into production – we might finally find that the Talking Heads were correct: in the world of flash memory we are on the road to no-wear…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

{kind=link}
Thanks for the post and the interesting analogy. With a EE degree (quite a while ago though), I can follow your explanation but still think the analogy with students is cute.
I have been following this series on flash memory and get well educated. As the big data world becomes more and more interested in hybrid storage system, I’m sure more people will pay attention to the development of non-volatile memory technologies. Keep up the good work!
Hi,
Thank you for the information. I had one more question.
How does a human tells a computer or a programmer that which floating gate is to be filled with charges and which floating gate is to be left untouched.
I know it is a purely mechanical but I am trying to find the exact answer.
Please could help ?
Well ultimately this is a case of hardware electronics, so commands are sent to the flash chips via electrical signals to the pins on the chips.
You can read about that sort of thing here: http://www2.lauterbach.com/pdf/nandflash.pdf
Hi, I’m deeply thankful for these articles and I really enjoy the way they are exposed. So a big thank you!
Now, I don’t have a deep understanding of this type of technology, but something has come to my mind.
I understand that SLC, MLC and TLC differs because of those thresholds and the Oxide Layer (if I got it right) eventually deteriorates. So, from this point of view, MLC and TLC are just more complex SLC, trying to bypass those physical limitations with different strategies. My question is, can you convert a MLC/TLC SSD into SLC? If the cells fail to a point where the SSD becomes unpractical (i guess there’s some kind of SMART-like control that prevents you from using it once you reach a certain threshold), can you like erase everything, halve the capacity (or reducing it even more) and convert it to SLC?
From what I understand MLC and TLC have more controllers of the “buckets” thresholds, so they are capable to mimic SLC, from this point of view. Is it possible? Are there any substantial difference that can prevent you from doing it? Hope it makes sense, thank you.
To my knowledge there is no physical reason why that wouldn’t be possible at the cell level, although this is getting into a level of detail that is beyond my experience. However, it would require more complex management within the NAND flash packages, for example in the way that data is read into the memory registers which are the half-way house before data is read off the chip. My previous employer, Violin Memory, experimented with using MLC flash in “SLC mode”, which is similar to what you suggest.
What we do know is that no SSD vendor, or flash fabricator, is going to expose the controls to allow you to do something like this. It would be untried, untested and unsupported if they did, not to mention bad for their business!