
Storage for DBAs: It’s a familiar worn-out story. A downtrodden and oppressed population are rescued from their plight by a mysterious superhero. Over time they come to rely on this new superbeing – taking him for granted even, complaining when he isn’t immediately available to save them and alleviate their pain. As the years progress, memories of the “old days” fade away while younger generations grow up with no concept of how bad things used to be. Our superhero is no longer special to us, in fact we feel he isn’t doing enough. As he grows old we grumble and complain while he desperately looks to the skies for someone younger, faster and with greater powers to relieve him of his burden: the burden of our expectation.
No it’s ok, I haven’t taken a creative writing course and taken this opportunity to practice my (lack of) skills on you. The aging superhero in my story is the humble disk drive.
The disk drive has been around, in one form or another, for well over 50 years. It’s changed, of course (the original IBM RAMAC 305 weighed over a ton) and capacity figures have changed too. But the mechanical aspects of storing data on a spinning magnetic disk – the physics of the design – remain the same.
Terminology
 A hard disk drive consists of a set of one or more platters, which are disks of non-magnetic material such as aluminium. The platters spin at a constant speed on a common axle which we call a spindle – and by extension we often refer to the entire hard drive unit as a spindle too. The platters are coated in a thin layer of ferromagnetic material, which is where data is stored in binary form in concentric circles which we call tracks. Each track is divided into equal-sized segments called sectors and it is these that hold the data, along with additional overheads such as error correction codes. Traditionally, a sector contained 512 bytes of user data – but modern disks conforming to the Advanced Format standard use 4096 bytes for a sector. Data is read and written by a read/write head located on the end of a movable actuator arm which can traverse the platter – and of course with multiple and/or double-sided platters there will be multiple heads.
A hard disk drive consists of a set of one or more platters, which are disks of non-magnetic material such as aluminium. The platters spin at a constant speed on a common axle which we call a spindle – and by extension we often refer to the entire hard drive unit as a spindle too. The platters are coated in a thin layer of ferromagnetic material, which is where data is stored in binary form in concentric circles which we call tracks. Each track is divided into equal-sized segments called sectors and it is these that hold the data, along with additional overheads such as error correction codes. Traditionally, a sector contained 512 bytes of user data – but modern disks conforming to the Advanced Format standard use 4096 bytes for a sector. Data is read and written by a read/write head located on the end of a movable actuator arm which can traverse the platter – and of course with multiple and/or double-sided platters there will be multiple heads.
That’s where disk’s superpowers came from: the winning combination of a moving head and the concentric tracks of data. These days it almost seems like a flaw, but to appreciate the magic you need to consider the technology that disk replaced.
The Bad Old Days
 Before disk, we had tape – a medium still in use today for other purposes such as backups. A big spinning reel of magnetic tape can transfer data in and out pretty fast (i.e. it has a high bandwidth) when the I/O is sequential, because the blocks are stored contiguously on the tape. But any kind of random I/O requires a mechanical delay (i.e. high latency) as the tape is wound backwards or forwards to locate the starting block and place it in front of the fixed read/write head. The time taken to locate the starting block is known as the seek time – a term that has haunted storage for decades.
Before disk, we had tape – a medium still in use today for other purposes such as backups. A big spinning reel of magnetic tape can transfer data in and out pretty fast (i.e. it has a high bandwidth) when the I/O is sequential, because the blocks are stored contiguously on the tape. But any kind of random I/O requires a mechanical delay (i.e. high latency) as the tape is wound backwards or forwards to locate the starting block and place it in front of the fixed read/write head. The time taken to locate the starting block is known as the seek time – a term that has haunted storage for decades.
When disk arrived it seemed revolutionary (pardon the pun). Like tape, disk used spinning magnetic media, but unlike tape, the read/write head could now move – allowing drastically reduced seek times. Want to move from reading the last sector on the disk to the first? No problem, the actuator arm simply moves across the tracks and then the platter rotates to find the first sector. A tape, on the other hand, would need to rewind the entire reel.
So, ironically, disk represented a massive leap forward for the performance of random I/O. How the mighty have fallen… but I’m going to save any talk of performance until the next post. For now, we need to finish off describing the basic layout of disk.
On The Edge
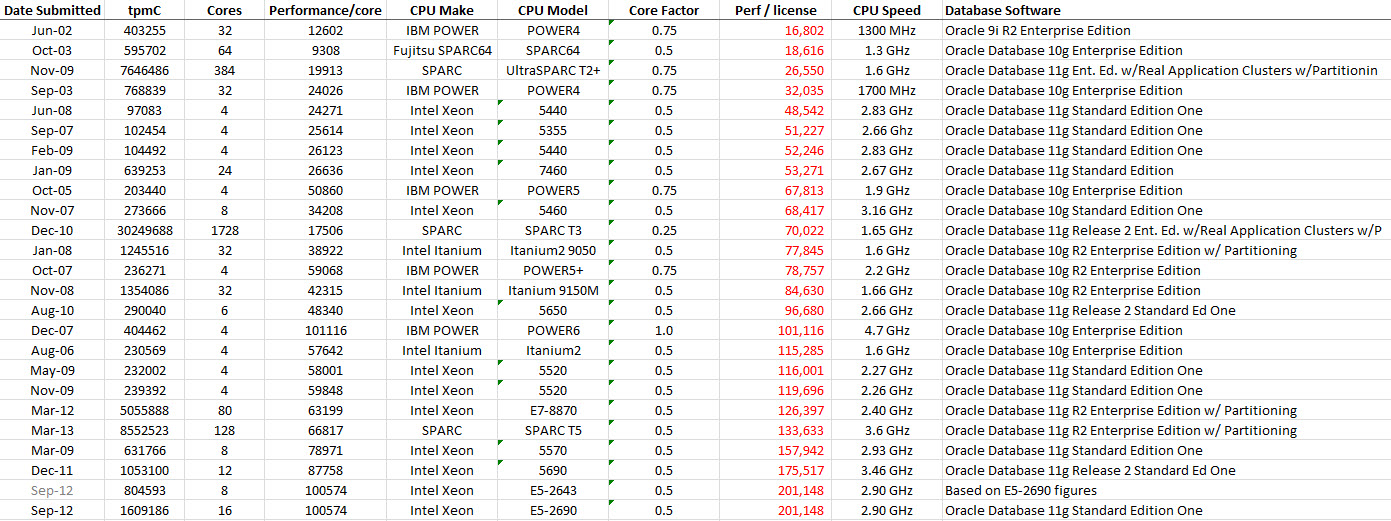
 The picture on the right shows a traditional disk layout, where individual sectors (C) spread out across tracks (A) in the same way as a slice of cake or pie. If you consider a set of sectors (B – all those shaded in blue) you can see that they get longer the further towards the edge they get. How long does it take to read three consecutive sectors on a track, such as those highlighted green (D)? In the diagram those three sectors cover 90 degrees of the platter, so the time to read them would be one quarter of a revolution. And crucially, that would be the same no matter how far in or out they were from the edges.
The picture on the right shows a traditional disk layout, where individual sectors (C) spread out across tracks (A) in the same way as a slice of cake or pie. If you consider a set of sectors (B – all those shaded in blue) you can see that they get longer the further towards the edge they get. How long does it take to read three consecutive sectors on a track, such as those highlighted green (D)? In the diagram those three sectors cover 90 degrees of the platter, so the time to read them would be one quarter of a revolution. And crucially, that would be the same no matter how far in or out they were from the edges.
In this traditional model, each sector contains the same amount of data (512 or 4096 bytes plus overheads). Since data is nothing more than bits (zeros and ones) we can say that the density of those bits is greater towards the centre of the platter and lower at the edge. In other words, we aren’t really utilising all of the available platter surface as we move further towards the edge. This directly affects the capacity of the drive, since less data is being stored than the platter can physically allow. There are solutions to this, however – and the most common solution is zoned bit recording.
In The Zone
 To ensure that all of the available surface is used on each platter, many modern disk drives used a technique where the number of sectors per “slice” increases towards the edge of the disk. To simplify this design, tracks are placed into zones, each of which has a defined number of sectors per track. The result is that outer zones squeeze more sectors on to each track than inner zones. This has the benefit of increasing the capacity of the drive, because the surface is more efficiently used and bit densities remain consistently high.
To ensure that all of the available surface is used on each platter, many modern disk drives used a technique where the number of sectors per “slice” increases towards the edge of the disk. To simplify this design, tracks are placed into zones, each of which has a defined number of sectors per track. The result is that outer zones squeeze more sectors on to each track than inner zones. This has the benefit of increasing the capacity of the drive, because the surface is more efficiently used and bit densities remain consistently high.
But zoned bit recording also has another interesting effect: on the outer edge, more sectors now pass under the head per revolution. To put that more simply, the outer edge has a higher transfer rate (i.e. bandwidth) than the inner edge. And since most drives tend to number their tracks starting at the outer edge and working inwards, the result is that data stored at the logical start of a drive benefits from this higher bandwidth while data stored at the end experiences the opposite effect.
This is nothing to do with latency though, this is purely a bandwidth phenomenon. Latency is a whole different discussion – and as such, the subject of a whole different post…











 Storage for DBAs: The strange thing about enterprise databases is that the people who design, manage and support them are often disassociated from the people who pay the bills. In fact, that’s not unusual in enterprise IT, particularly in larger organisations where purchasing departments are often at opposite ends of the org chart to operations and engineering staff.
Storage for DBAs: The strange thing about enterprise databases is that the people who design, manage and support them are often disassociated from the people who pay the bills. In fact, that’s not unusual in enterprise IT, particularly in larger organisations where purchasing departments are often at opposite ends of the org chart to operations and engineering staff.


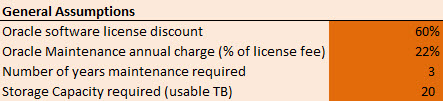
 There are two points I want to make here. One is that the cost of storage is often relatively small in terms of the total cost. If a large amount of money is being spent on licensing the environment it makes sense to ensure that the storage enables better performance, i.e. results in a better return on investment.
There are two points I want to make here. One is that the cost of storage is often relatively small in terms of the total cost. If a large amount of money is being spent on licensing the environment it makes sense to ensure that the storage enables better performance, i.e. results in a better return on investment.






 Forget everything else. Latency is the critical factor because this is what injects delay into your system. Latency means lost time; time that could have been spent busily producing results, but is instead spent waiting for I/O resources.
Forget everything else. Latency is the critical factor because this is what injects delay into your system. Latency means lost time; time that could have been spent busily producing results, but is instead spent waiting for I/O resources.



