
In the last post in this series I discussed some of the various tasks that need to be performed by the flash translation layer – the layer of abstraction that sits between us and the raw NAND flash on which we desire to store our data. One of those tasks is the infamous garbage collection process (or “GC”) – and in these next couple of posts I’m going to look into GC a little deeper.
But first, let’s consider what would happen on a flash system if there were no GC at all.
Why We Need Garbage Collection
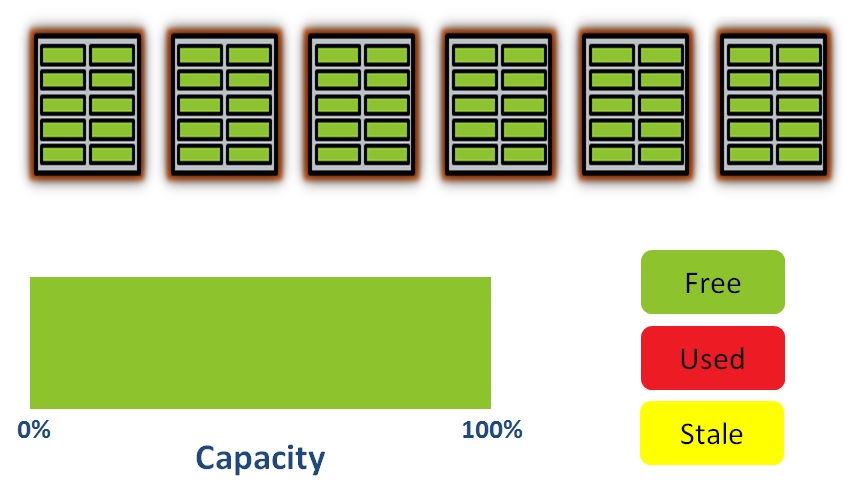
Let’s imagine a very simple flash system comprising of just five blocks, each with just ten pages. In the beginning, all the pages are empty, so we can say that 100% of the capacity is Free:
There’s no point in wasting all that lovely flash, so I’m going to write some data to it. Remember that a write operation in the world of flash is known as a program operation and it takes place at the page level. So here goes:
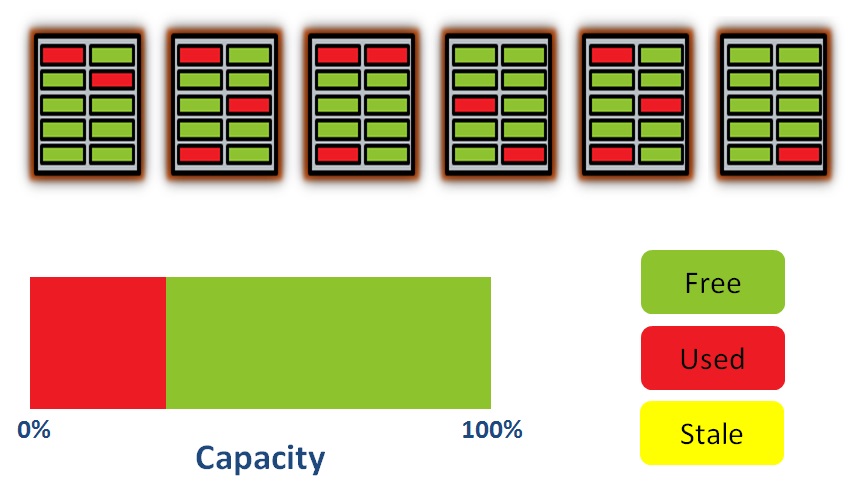
You can see a couple of things happening here. First of all, some of the capacity is now showing as Used. Secondly, you can see that our wear levelling algorithm has kicked in to spread the data over all the blocks fairly evenly. Some blocks have more used pages than others, but the wear levelling doesn’t have to be exact, just approximate. Let’s add some more data:
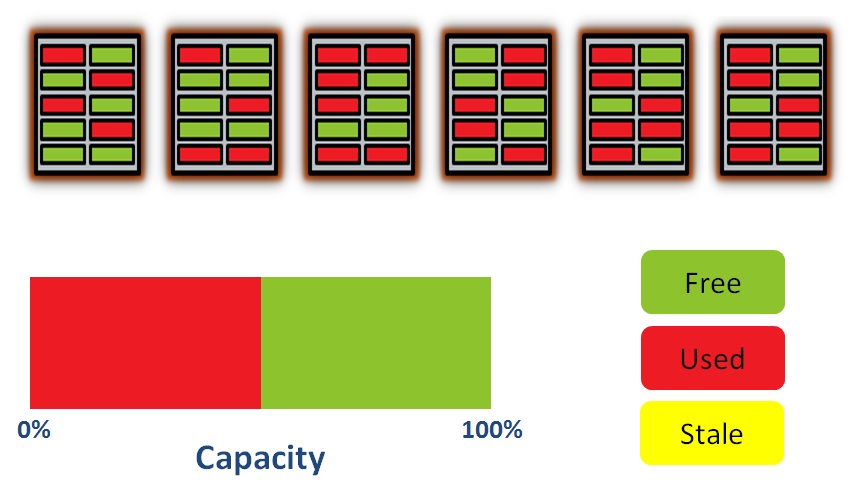
Now we’re at 50% Used – and again the data has been spread evenly for the purposes of wear levelling. The flash translation later is also taking care of logical to physical block mapping, so although data has been spread across multiple blocks it has the appearance of being sequential when accessed by the calling application.
Time For Some Updates
So far so good. But at some point we’re probably going to want to update some of the existing data. And as we know, on NAND flash that’s not straightforward because used pages cannot be updated without the entire block first being erased. So for now we simply write the updated data to an empty page and mark the old page as stale. The logical to physical block mapping allows us to simply redirect the logical address of an updated block to the physical address of the new page:
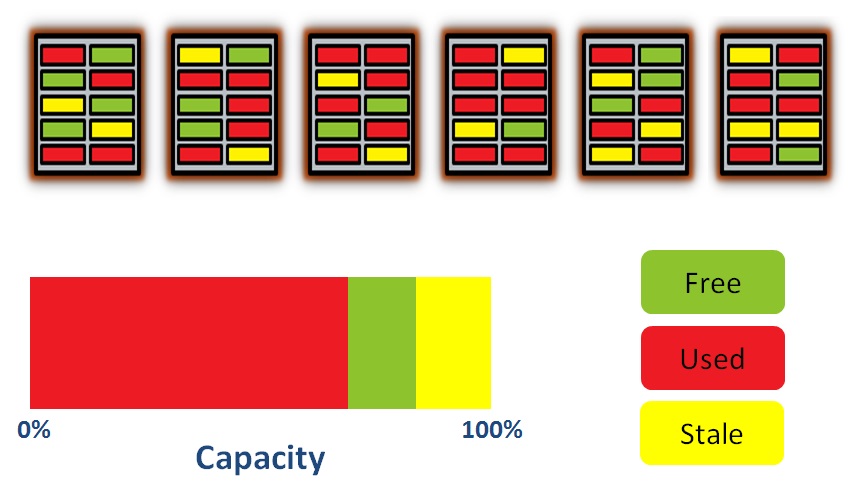
See how some of the blocks which were showing as Used (in red) are now showing as Stale (in yellow)? And of course the capacity graph is now showing a percentage of the total capacity as being stale. But have you also noticed that we are approaching the point where we can never free up the stale pages?
Never forget that NAND flash can only be erased at the block level. In the above example, the first (left-most) block has two stale pages and four used pages. In order to free up those stale pages I need to copy the used pages somewhere else and then erase the block. If I don’t do that very soon, I’m going to run out of free pages in the other blocks and then … I’m screwed:
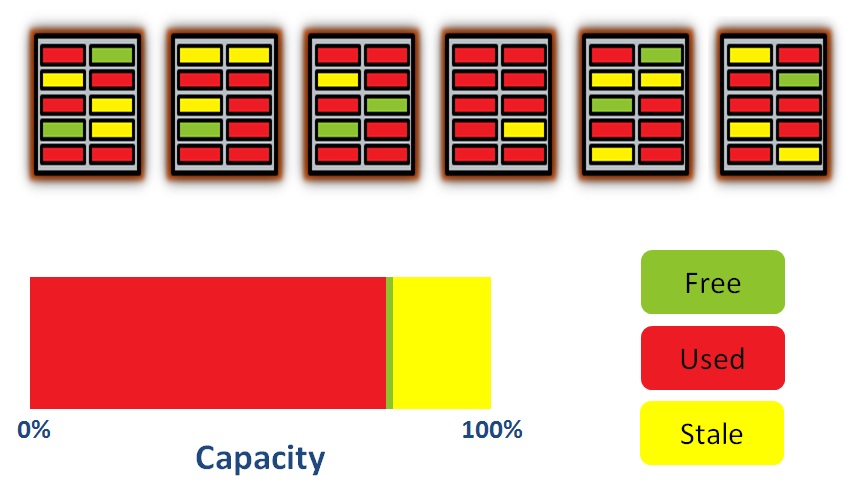
This situation is a disaster, because at this point I can never free up the stale blocks, which means I’ve effectively just turned my flash system into a read only device. And yet if you look at the capacity graph, it’s only around 75% full of real data (the stuff in red). So does this mean I can never use 100% of a flash device?
The Return of Over-Provisioning
Earlier in this Storage for DBAs blog series I wrote an article about one of my least favourite practices in the world of hard disk drives: over-provisioning. I now have to own up and confess that in the world of flash we do pretty much the same thing, although for slightly different reasons (and without the massive overhead of power, cooling and real-estate costs that makes me so mad with disk).
To ensure that there is always enough room for garbage collection to continue (as well as to allow for things like bad blocks, wear levelling etc), pretty much every flash device vendor (from SSDs through to All Flash Arrays) uses the same trick:
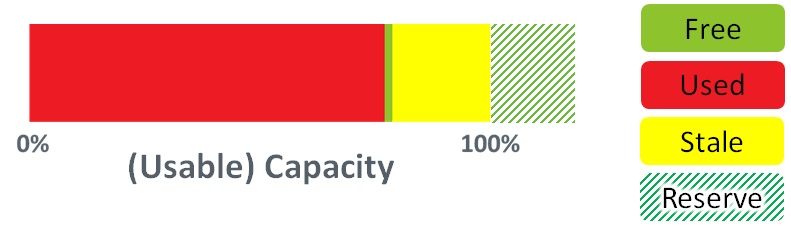
Yep, there’s more flash in your device than you can actually see. For example, rip off the covers of a 400GB HGST Ultrastar SSD800MM (the SSD that used to be found in XtremIO arrays) and you’ll find 576GB of raw flash. There’s 44% more capacity on the device than it advertises when you access it. This extra area is not pinned by the way, it’s not a dedicated set of blocks or pages. It’s just mandatory headroom that stops situations like the one we described above ever occurring.
The Violin Way

Since I work for Violin Memory it would be remiss of me not to discuss the concept of format levels at this point. When you buy flash in the form of SSDs, or flash arrays that contain SSDs, the amount of over-provisioning is generally fixed. Almost all SSDs have a predefined over-provision area and that cannot be changed (if there is an SSD on the market that allows this, I am not aware of it).
One of the advantages we have at Violin is that we build our arrays from the ground up using NAND flash chips rather than pre-packaged SSDs – our flash is located on our unique Violin Intelligent Memory Modules (VIMMs). This means we have control down to the NAND flash level – and one of the benefits here is that we can choose how much over-provisioning is required based on workload. At Violin we call this the format level of an array and we allow customers to set it when they take delivery (it can also be changed at a later time but obviously requires a reformat of the array).

I see this as a great benefit because some workloads are very read-intensive and so a large over-provision would essentially be a waste of good flash. Conversely some workloads are so write-heavy that the hard limits found on an SSD device would not be suitable. In general I believe that choice (as long as it comes with advice) is a good thing.
In the next post we’ll look at garbage collection some more, in particular the concept of background versus foreground garbage collection, as well as cover the infamous write cliff. But for now, just remember: no matter what form of flash you are using, in order for it to work and perform properly, something somewhere has to take out the trash…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

Nice post! Liked the pic with the garbage trucks :p
Overthinking all this, I argue that garbage collection is a misnomer. The garbage collection does not actually collect garbage. It collects chunks of good data, glues it together in a more compact and efficient way, and then thrashes the remaining garbage completely (by clearing the flash cells) to free up the space for future writes with new valuable data…
Hello Bart!
I agree. I blame those Java developers for inventing the phrase, which the flash industry seems to have adopted. In fact, my esteemed Violin colleague Steve Willson gives an excellent talk on flash management in which he shows garbage collection as essentially a massive game of Tetris where blocks need to be fitted into the available holes in order to reach the best efficiency. I love that image and may even steal it for the next post.
Thanks for stopping by 🙂
Would you mind linking the talk by your esteemed Violin colleague Steve Wilson? I would be interested to watch it!
I’m afraid that talk wasn’t recorded. Steve now works for DellEMC’s DSSD business unit and so can be found travelling around Europe spouting nonsense to anyone with a multimillion dollar budget.
I learnt a lot from Steve during our time working together at Violin. One of the main things I learnt was that after delivering any kind of pitch or presentation, upon returning to the office and being asked by your colleagues “How did it go?” one should always employ the standard response: “I was brilliant.”
Thanks Chris. I think you’ll find I was brilliant 🙂 You don’t need anything approaching a million for DSSD (or even a fraction of that…call for quotes). I seem to mainly be in Germany at the moment!
What do you mean to say by “But have you also noticed that we are approaching the point where we can never free up the stale pages?”..We can always free up stale pages in any block by just copying used pages somewhere then deleting entire block and writing back used pages in the block again.
May you please clear me on this..
I think maybe you missed my point. I am talking through a scenario and leading the reader through the design challenges. Ultimately, I am saying exactly what you have also just said in your comment – in fact I say it in the very next sentence to the one you quote. So, ultimately, I think we are in agreement.
Thanks man. Just to confirm you mean that there may come a time when all my blocks has only stale and used pages. So just to ensure that this situation never happens I keep running garbage collector algorithm from time to time so that there are always some free pages.
Exactly right. And, to continue that train of thought, if you write new or changed data fast enough, there may come a time when you actually have to slow down (or rather, queue) the writes so that the garbage collector can keep up.
Thanks !! Your article is really helpful and easy to understand..
Very good read indeed.
I have a followup question regarding the following statement:
“To ensure that there is always enough room for garbage collection to continue (as well as to allow for things like bad blocks, wear levelling etc), pretty much every flash device vendor (from SSDs through to All Flash Arrays) uses the same trick”
So, the extra headroom area is used when we run into a situation where the garbage collection process is not keeping up with the amount of write activity and we are hitting a state where not enough space is available to copy the used blocks somewhere else in order to erase them?
No, actually there is no specific area allocated or reserved for garbage collection. As a simplification, most flash systems write in a circular manner, so that the oldest blocks and pages are re-used first. The extra, unadvertised, capacity is just a way of ensuring that the system does not hit gridlock.
Think of a self-contained city traffic system containing roads, junctions and so on – let’s say the total road length is X. To keep things simple, let’s also imagine that all of the vehicles in this network have the same length of Y. The maximum number of vehicles you could fit in this system is simply X / Y. But this would leave no room between the vehicles and your traffic system would be totally gridlocked. To get traffic flowing you need some space distributed between all of your vehicles, right? So you need to maintain an extra “overprovisioned” length of road which is outside of your calculations of X / Y and which acts as a sort of buffer. But just like with flash arrays, it would not make sense for this extra length of road to all be in one place… it needs to be divided and distributed between all your vehicles.
You can extend this analogy further, too. As with flash arrays or SSDs, the larger your overprovisioned length of road, the faster your traffic system is likely to be able to flow… but the less cost efficient your design is, since this additional road has a cost which cannot be recouped. Some flash arrays deliberately use a lower amount of overprovisioned area to sacrifice sustained write performance for better cost efficiency. This makes then appear better value for money, but you should beware their performance when approaching full capacity.
Love this analogy. Even 3 years later it make sense (we still use cars evidently).
Garbage collection seems to be analogous to the defrag utility used to rewrite data in contiguous LBAs after several delete operations in a HDD. In order to do this we need a certain amount of unused LBAs to temporarily move the data and rewrite them contiguously.
l love this blog post, how author delves into the crucial role of garbage collection (GC) in flash memory systems. They vividly illustrate how without effective GC, stale data accumulates, rendering the flash storage nearly unusable. The concept of over-provisioning is introduced as a smart solution, ensuring smooth GC operations and optimal flash performance. This post provides valuable insights into the intricacies of flash storage management.
Does the ssd store new/updated data in the deleted block or does it use empty pages in other blocks?
That post is almost a decade old and I haven’t worked in that industry for half that time, but in principle the new data is stored in free pages within any block which contains them. Once the block is deleted, it becomes freshly available with a full compliment of free pages just waiting for new data to be stored in them – either by a user or by the garbage collector moving active pages from a block it wants to erase.