
For the last couple of posts in this series I’ve been banging on about the importance of garbage collection (GC) in a flash system. I attempted to show you what happens if you don’t perform any GC at all (clue: you turn your flash device into a slow ROM), but clearly in the real world every flash array or SSD vendor has GC technology built into their flash translation layer. So why am I going to devote yet another post to it?
Predictable Performance

When you consider the performance of a system, what’s the number one requirement on your list? Is it “fast”? I would argue not. In my opinion, the first and most important requirement when considering performance is predictability. If you know how a system will perform at any time then (even if you would prefer things to happen faster) you can plan accordingly. If the same repeatable action behaves completely differently over random samples, how can you ever consider it reliable?
Cast your mind back to the post about flash blocks and pages. Remember that reads happen at the page level, as do writes (known as program operations when working with NAND flash) but only empty pages can be programmed. To make a page empty you must perform an erase operation – and, crucially, these happen at the block level thereby affecting an entire set of pages.
As you fill up your flash device, pages containing data must be relocated in order to free up blocks so that they can be erased. At this point there are two pieces of bad news to consider:
First of all, in general each flash die can only perform one operation at a time (sometimes this is one operation per plane but that really doesn’t detract from the point). That means if you are performing an erase operation on block A, a read operation from a page in block Z on the same die has to be queued. It’s a completely different block – one of thousands on the same die – but the operation is queued nonetheless.
The second bit of news is that erase operations are slow… really slow. For MLC flash we’re talking maybe 3 milliseconds, which is an age when you compare it to the ~50 microseconds it takes to perform a read. Program operations are also slower than reads (but faster than erases) and they also have to be queued.
So based on all this information, a user who simply reads data at a predictable rate may suddenly see their latency spike up to around 60x higher than the 50us they are expecting if their read gets queued behind an erase. That doesn’t sound like fun does it?
Background vs Active / Foreground Garbage Collection

We know that garbage collection has to try and take care of erases in order to stop you running out of space as you fill up your flash. But let’s now consider this in terms of the performance problems caused by “user operations” (i.e. active reads and writes from the host) queuing up behind “background operations” (i.e. activity caused by the flash translation layer doing its job). Clearly the latter will affect the former if we are not careful. It therefore makes sense that we should try and perform all of our background operations at times when they will not cause problems to the users. As you know if you’ve read my blog before, I love an analogy… so let’s consider garbage collection a bit like the process of washing dishes at a busy restaurant.
A restaurant only has a finite number of plates, glasses, cutlery etc, so once stuff is used it has to return to the kitchen and be washed ready for reuse. In a well-functioning restaurant this process takes place without disrupting the flow of cooked meals leaving the kitchen and being served to customers. In the same way, if our flash garbage collection is taking place in a manner which does not affect the active I/O operations of our users, this is known as background garbage collection (BGC). You can consider BGC “a good thing”, since it “hides” the impact of erase operations and results in more stable, predictable I/O times from the host. In other words, the kitchen runs smoothly and our customers are happy. Bravo.
On the other hand, if our dishes are not being washed fast enough in the kitchen of our restaurant, at some point there will be a shortage of clean plates etc and the customers will have to wait. Likewise, if more data is being changed than BGC can keep up with, the flash device is now running out of free space in which to program incoming writes. This means we have to switch into a different mode called active garbage collection (AGC), sometimes also described as foreground garbage collection. In AGC, user I/O inevitably ends up queuing behind background operations – and in severe cases we have to throttle user I/O requests because they cannot be serviced in time. Yes, we actually have to tell the waiters not to take any more orders until we can get our act together in the kitchen.
You might remember from my previous post that all flash vendors overprovision their flash to allow an additional working area where new writes can land while stale pages are being erased. In the same way, most restaurants probably have more plates and cutlery than they have table settings out front. It helps – and the more you overprovision, the more breathing space you have – but at some point if you don’t take care of your dirty dishes you will still run out of clean ones.
The Infamous Write Cliff
There has been a lot of talk about the write cliff by various commentators, flash vendors and bloggers over the years. I’ve read articles that say it’s no longer a problem (“in most SSD arrays”), articles that show it causing significant problems and white papers on how to avoid it.
My advice is to keep it simple: your flash device has an over-provisioned “buffer zone” which you may or may not be able to see (on Violin you can actually configure it). If you change more data on your flash device than the background garbage collection algorithm can keep up with, you will eat into this buffer zone until you hit active garbage collection. Keep pushing your device at this point and you will see the latency rise as the number of IOPS falls. It’s a simple as that.
My good buddy Maxim from Violin’s amazing engineering team demonstrated this to me in real life by deliberately limiting the ability of background garbage collection on a test system and then hitting it with lots of writes. Here’s the result:
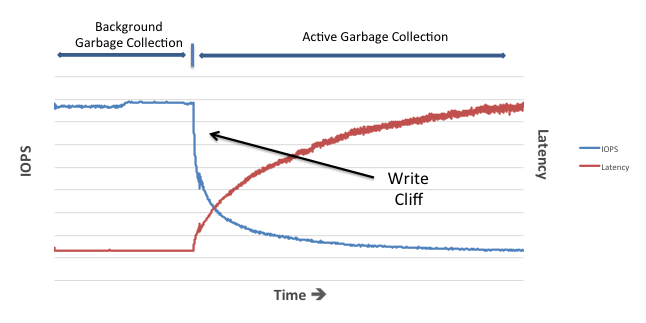
This same pattern can be seen in numerous other places on the internet; for example, in the Preconditioning Curve graphs of reviews of SSDs. In fact, there are only two possible scenarios where a flash device won’t hit the write cliff (assuming you push it hard enough):
- Flash devices (mainly SLC) which can perform garbage collection really quickly and have lots of overprovisioned space (e.g. the Violin Memory 6616 array frequently used for setting benchmark records)
- Flash devices where the limited ingest capability means they can never accept enough writes to exhaust their overprovisioned space
That last one might seem contentious, but think about it: it’s a simple fact of NAND flash that erases are slower than writes (programs). This means if you are able to perform enough writes then eventually you will always exhaust any finite overprovisioned buffer space. At that point, writes must slow down to the speed of erases. As the theory of constraints says, “a chain is no stronger than its weakest link“…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

Hello Chris,
I’m writing an article on SSDs in the industrial and military environments and found your blog. Great stuff. I would like to use your image at https://flashdba.files.wordpress.com/2014/11/active-vs-background-garbage-collection.png in my article. Of course with proper citation. Would that be OK?
Thanks,
David
davidl@chassisplans.com
No problem, go ahead!