
In the previous post of this series I outlined three basic categories of All Flash Array (AFA): the hybrid AFA, the SSD-based AFA and the ground-up AFA. This post addresses the first one and is therefore aimed at answering one of the questions I hear most often: why can’t I just stick a bunch of SSDs in my existing disk array?
Data Centre Dinosaurs
Disk arrays – and in this case we are mainly talking about storage area networks – have been around for a long time. Every large company has a number of monolithic, multi-controller cache-based disk arrays in their data centre. They are the workhorses of storage: ever reliable, able to host multiple, mixed workloads and deliver predictable performance. Predictably slow performance, of course – but you mustn’t underestimate just how safe these things feel to the people who are paid to ensure the safety of their data. Add to this the full suite of data services that come with them (replication, mirroring, snapshots etc) and you have all that you could ask for.

Except of course that they are horribly expensive, terribly slow and use up vast amounts of power, cooling and floor space. They are also a dying breed, memorably described by Chris Mellor of The Register as like outdated battleships in an era of modern warfare.
The SSD Power-Up
Every large vendor has a top-end product: EMC’s VMAX, IBM’s DS8000, HDS’s VSP… and pretty much every product has the ability to use SSDs in place of disk drives. So why not fill one of these monsters with flash drives and then call it an “All Flash Array”? Just like in those computer games where your spacecraft hits a power-up and suddenly it’s bigger and faster with better weapons… surely a bunch of SSDs would convert your ageing battleship into a modern cruiser with new-found agility and seaworthiness. Ahoy! [Ok, I’ll stop with the naval analogies now]
Well, no. And to understand why, let’s look at how most disk arrays are architected.
The Classic Disk Array Architecture
Let’s consider what it takes to build a typical SAN disk array. We’ll start with the most obvious component, which is the hard disk drive itself. These things have been around for decades so we are fairly familiar with them. They offer pretty reasonable capacity of up to 4TB (in fact there are even a few 6TB models out now) but they have a limitation with regard to performance: you are unlikely to be able to drive much more than 200 transactions per second.

At this point, stop and think about the performance characteristics of a hard disk drive. Disks don’t really care if you are doing read or write I/Os – the performance is fairly symmetrical. However, there is a drastic difference in the performance of random versus sequential I/Os: each I/O operation incurs the penalty of latency. A single, large I/O is therefore much more efficient than many, small I/Os.
This is the architectural constraint of every hard disk drive and therefore the design challenge around which we much architect our disk array.
In the next section we’re going to build a disk array from scratch, considering all the possibilities that need to be accounted for. If it looks like it will take too long to read, you can skip down to the conclusion section at the end.
Building A Disk Array
We’re now going to build a disk array, so the first ingredient is clearly going to be hard drives. So let’s start by taking a bunch of disks and putting them into a shelf, or some other form of enclosure:

At this point the density is limited by the number of disks we can fit into the enclosure, which might typically be 25 if they are of the smaller form factor or up to around 14 if they are the larger 3.5 inch variety.
Next we’re going to need a controller – and in that controller we’re going to want a large chunk of DRAM to act as a cache in order to try and minimise the number of I/Os hitting the disk enclosure. We’ll allocate some of that DRAM to work as a read cache, in the hope that many of the reads will be hitting a small subset of the data stored, i.e. the “hot” blocks. If this gamble is successful we will have taken some load off of the disks – and that is a Good Thing:
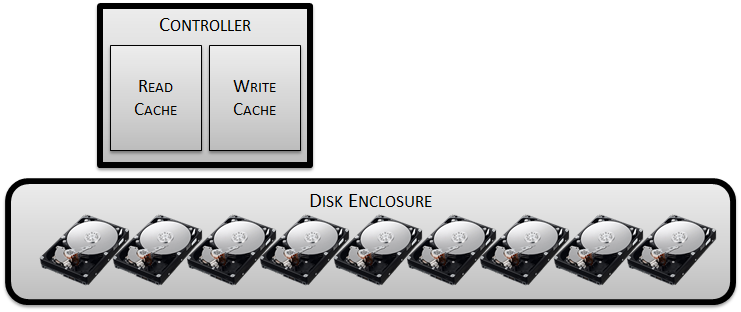
The rest of the DRAM will be allocated to a write cache, because clearly we don’t want to have to incur the penalty of rotational latency every time a write I/O is performed. By writing the data to the DRAM buffer and then issuing the acknowledgement back to the client, we can take our time over writing the data to the persistent storage in the disk enclosure.
Now, this is an enterprise-class product we are trying to build, so that means there are requirements for resiliency, redundancy, online maintenance etc. It therefore seems pretty obvious that having only one controller is a single point of failure, so let’s add another one:
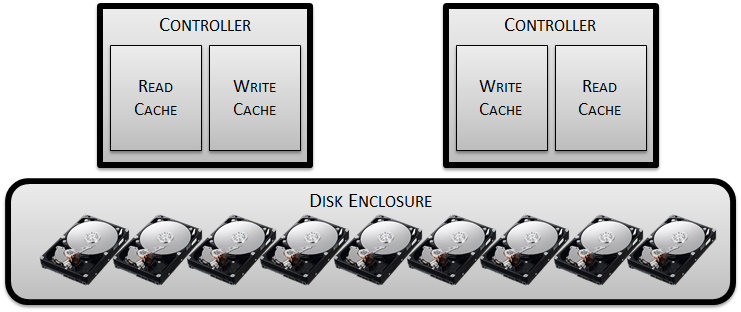
This brings up a new challenge concerning that write cache we just discussed. Since we are acknowledging writes when they hit DRAM it could be possible for controller to crash before changed blocks are persisted to disk – resulting in data loss. Also, an old copy of a block could be in the cache of one controller while a newly-changed version exists in the other one. These possibilities cannot be allowed, so we will need to mirror our write cache between the controllers. In this setup we won’t acknowledge the write until it’s been written to both write caches.
Of course, this introduces a further delay, so we’ll need to add some sort of high speed interconnect into the design to make the process of mirroring as fast as possible:
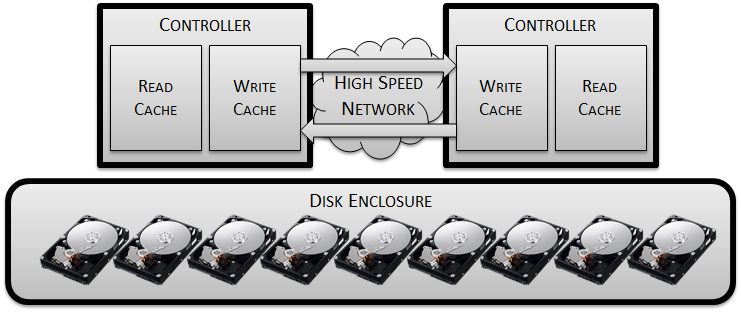
This mirroring may protect us from losing data in the event of a single controller failure, but what about if power to the entire system was lost? Changed blocks in the mirrored write cache would still be lost, resulting in lost data… so now we need to add some batteries to each controller in order to provide sufficient power that cached writes can be flushed to persistent media in the event of any systemic power issue:
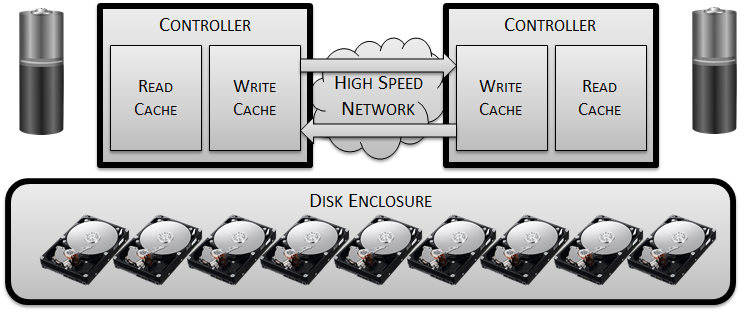
That’s everything we need from the controllers – so now we need to connect them together with the disks. Traditionally, disk arrays have tended to use serial architectures to attach disks onto a back end network which essentially acts as a loop. This has some limitations in terms of performance but when your fundamental building blocks are each limited to 200 IOPS it’s hardly the end of the world:
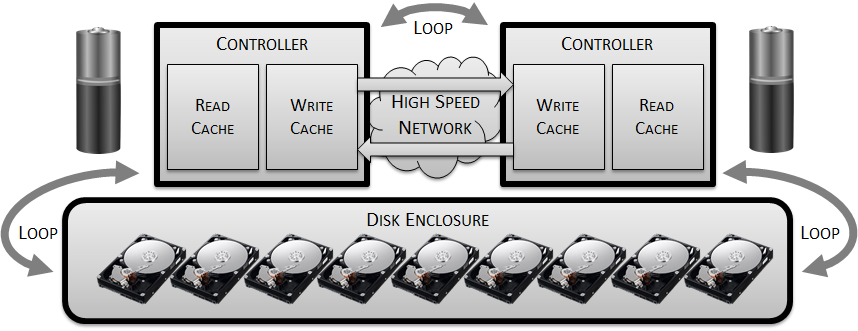
So there we have it. We’ve built a disk array complete with redundant controllers and battery-backed DRAM cache. Put a respectable logo on the front and you will find this basic design used in data centres around the world.
But does it still make sense if you switch to flash?
From HDD To SSD
Let’s take our finished disk array design and replace the disks with SSDs:
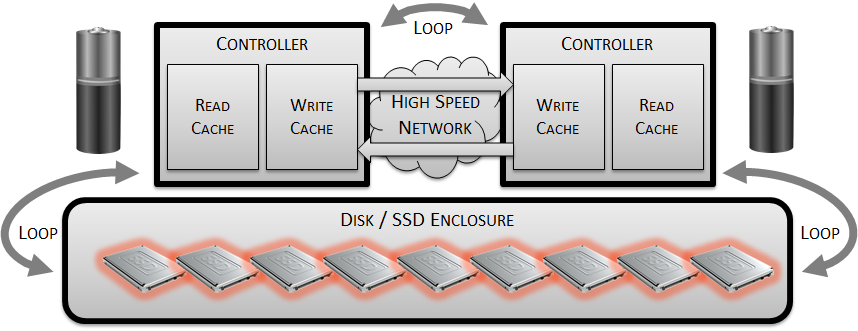
And now let’s take a moment to consider the performance characteristics of flash: the latency is much lower than disk, meaning the penalty for performing random I/Os instead of sequential I/Os is negligible. However, the performance of read versus write I/Os is asymmetrical: writes take substantially longer than reads – especially sustained writes. What does that do to all of the design principles in our previous architecture?
- With so many more transactions per second available from the SSDs, it no longer makes sense to use a serial / loop based back end network. Some sort of switched infrastructure is probably more suitable.
- Because the flash media is so much faster than disk (i.e. has a significantly lower latency), we can do away with the read cache. Depending on our architecture, we may also be able to avoid using a write cache too – resulting in complete removal of the DRAM in those controllers (although this would not be the case if deduplication were to be included in the design – more on that another time).
- If we no longer have data in DRAM, we no longer need the batteries and may also be able to remove or at least downsize the high speed network connecting the controllers.
All we are left with now is the enclosure full of SSDs – and there is an argument to be made for whether that is the most efficient method of packaging NAND flash. It’s certainly not the most dense method, which is why Violin Memory and IBM’s FlashSystem both use their own custom flash modules to package their flash.
Conclusion
Did you notice how pretty much every design decision that we made building the disk array architecture turned out to be the wrong one for a flash-based solution? This shouldn’t really be a surprise, since flash is fundamentally different to disk in its behaviour and performance.

Architecture matters. Filling a legacy disk array with SSDs simply isn’t playing to the strengths of flash. Perhaps if it were a low cost option it would be a sensible stop-gap solution, but typically the SSD options for these legacy arrays are astonishingly expensive.
So next time you look at a hybrid disk array product that’s being marketed as “all flash”, do yourself a favour. Think about the architecture. If it was designed for disk, the chances are it’ll perform like it was designed for disk. And you don’t want to end up with that sinking feeling…
This article is part of the Storage for DBAs series. If you found this series useful, you might also be interested in Databases in the Age of AI, which explores how AI agents are changing the assumptions at the heart of enterprise data systems.

Thank you for the article about the SSD disk array, you helped me a lot.
Thanks for the instructive article. Absolutely something to remember.
But by the way: I am quite sure that your battleship gets older between picture 1 and picture 2. And not sure if it is a battleship at all…
You make a valid point
Great article. Thank you. BTW, Marin Preiss caught the oversight. The new “battleship” is the USS Harry S Truman (CVN-75). The old battleship was the USS Franklin (CV-13) which was nearly lost in WW2 in the Battle of Leyte Gulf. Sorry. I am a history nerd.
Sure that makes since if you have an array with a looped back end, but most modern arrays used switched backend and have for a quite a while now. So yes if your trying to upgrade your 5+ year old array with SSD and expecting a huge improvement in speed you might be mistaken, but your vendor shouldn’t offer those options if they don’t make sense in that array. Also isn’t the DRAM going to be much quicker then the SSD or a FMD in the backend? If speed is the name of the game cache is still needed.
I disagree with your statement about cache. To pick a real-world example, the Violin Memory arrays sold by my current (soon to be former) employer do not use DRAM for caching reads or writes, yet are among the fastest all flash arrays in the industry and have been used in numerous benchmarks.