Before reading this page, you should first read the introductory article on 4k sector size storage to understand terms such as native mode, emulation mode, partial I/O and misalignment. If you don’t, it’s entirely possible that none of this will make sense. Of course, it’s entirely possible that none of this will make sense anyway, but that’s the risk you take reading the articles on this blog…!
Note also that when I wrote these articles on 4k I was employed by Violin Memory, a flash storage vendor who used Advanced Format to present their storage. I no longer work for Violin Memory but I believe the information here is still useful.
Oracle has had mixed levels of success introducing support for Advanced Format 4k storage devices into its software. In this article we will explore the various elements of Oracle that perform I/O and their ability to interact with storage which presents itself using the 4k native mode of Advanced Format.
But first, let’s take a second to understand what this means in more detail.
Physical and Logical Blocksize
I have here a Linux system connected to some external storage. Presented over fibre-channel are two LUNs, i.e two chunks of block storage, which Linux’s UDEV device mapper software has discovered and chosen to represent using the names sdc and sde (the “sd” meaning SCSI device):
[root@half-server4 mapper]# ls -l /dev/sd[ce]
brw-rw---- 1 root disk 8, 32 Mar 31 17:43 /dev/sdc
brw-rw---- 1 root disk 8, 64 Mar 31 17:43 /dev/sde
If we examine these devices in more detail, they appear to be very similar. Let’s start by issuing an inquiry using the sginfo tool (from the sg3_utils package) to see what sort of storage this is:
[root@half-server4 mapper]# sginfo -i /dev/sdc | egrep 'Vendor|Product'
Vendor: VIOLIN
Product: SAN ARRAY
[root@half-server4 mapper]# sginfo -i /dev/sde | egrep 'Vendor|Product'
Vendor: VIOLIN
Product: SAN ARRAY
No surprises there, they are both LUNs presented from a Violin array. Can I tell if they come from the same array? Yes I can:
root@half-server4 mapper]# sg_inq --page=0x83 /dev/sdc | grep "vendor specific"
vendor specific: 41148F00134:FS4KTEST:1AFC6D756956DD5E
[root@half-server4 mapper]# sg_inq --page=0x83 /dev/sde | grep "vendor specific"
vendor specific: 41148F00134:FS512TEST:1AFC6D753324F9D7
This tells me that both LUNs came from the same container “41148F00134” (essentially the same array) and that the LUNs were called FS4KTEST and FS512TEST. There’s a clue in those names (4k and 512), so let’s check the physical block size of each LUN:
root@half-server4 mapper]# blockdev --getpbsz /dev/sdc
4096
[root@half-server4 mapper]# blockdev --getpbsz /dev/sde
4096
Both have a physical block size of 4k – which in fact is the case with all Violin flash arrays, as well as EMC’s XtremIO arrays and a good number of other flash products, as well as many modern disk-based products. It sounds like both LUNs have identical properties, right? But hang on:
[root@half-server4 mapper]# blockdev --getss /dev/sdc
4096
[root@half-server4 mapper]# blockdev --getss /dev/sde
512
Here’s the big difference. The LUN called sdc has a logical block size of 4k, but the LUN called sde has a logical block size of 512 bytes. When I created these two LUNs in the Violin GUI, I chose different options for the “block size” property:
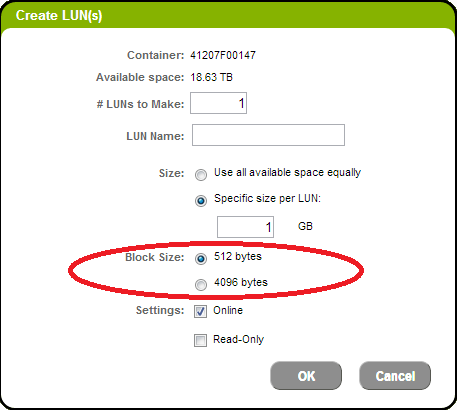
We can also confirm this with fdisk, which conveniently shows both the logical and physical block sizes:
[root@half-server4 mapper]# fdisk -l /dev/sdc | grep "Sector size"
Sector size (logical/physical): 4096 bytes / 4096 bytes
[root@half-server4 mapper]# fdisk -l /dev/sde | grep "Sector size"
Sector size (logical/physical): 512 bytes / 4096 bytes
What does this mean? It means that the LUN called sdc is using Advanced Format native mode, while the LUN called sde is using Advanced Format emulation mode. And although these LUNs are identical in every other way, this single difference is enough to justify (perhaps only in my mind) this entire page as well as its far-easier-to-read (again perhaps only in my mind) 4k sector size parent page.
Advanced Format: Native and Emulation Modes
The topic of Advanced Format is discussed in detail over on the 4k sector size page, so I’m not going to cover it again here. This page is more concerned with the specific use of Oracle on Advanced Format (heavily biased towards Linux). If you want to know more about Advanced Format in general you should consider following some of these links:
Wikipedia’s page on Advanced Format
IDEMA’s Advanced Format document repository
Seagate’s Tech Insight page on Advanced Format
Microsoft’s Dev Centre update on Advanced Format
However, because they are so critical, and because I don’t trust you to go and read the other stuff first, I will spend the next section outlining the four most important concepts you need to know, which are:
- Emulation Mode
- Native Mode
- Partial I/O
- Misaligned I/O
Whirlwind Summary
The sector size of a block storage device is the smallest unit of data that can be stored on it – each sector carries an overhead of metadata and error correction codes that are transparent to any system accessing it. Traditionally, storage devices such as disks have used a 512 byte sector size, but as devices continually increase in density this has come to result in an ever-increasing loss of capacity to metadata. Advanced Format devices use a sector size of 4096 bytes (4k), allowing eight times more data to be stored per set of metadata – increasing the format efficiency.
It is possible to present these new 4k sectors straight to any client (by which we mean an operating system, database or any application wanting to access it), but any I/O calls must be compatible with the new format. This type of presentation, i.e. where the client sees the devices as 4k, is known as native mode (or sometimes simply as “4k“). It only takes one entity in the stack to be unfamiliar with 4k for this approach to fail, which is why the design of Advanced Format also includes an alternative solution to bring backwards compatibility.

In the alternative, known as emulation mode (or simply as “512e“), the storage device has to effectively pretend that each sector is 512 bytes when in reality it is 4k. This is not as difficult as it sounds, because for a long time storage systems have been able to abstract a logical layer on top of the physical layer (consider, for example, a logical volume manager). While addresses in the physical layer map exactly to physical sectors, in 512e the logical layer has addresses that map to 512 byte chunks within those physical blocks. The benefit here is that older operating systems and applications which do not understand 4k native storage can work quite happily with 512e.
But what is actually happening underneath? In emulation mode, a process writing data in a block of 512 bytes causes additional unseen work to take place in the background, since the storage system has to read all 4k of data into memory, change the single 512 byte block in question and then write the whole 4k sector back to persistent storage. This is called a partial I/O (or a “partial write“) and results in a read modify write operation. In large numbers, this is potentially bad news for performance. It is also possible that the start of a logical block does not line up with the start of a physical block, meaning that I/Os will overlap the boundaries of physical sectors. This is called misaligned I/O (or “unaligned I/O“) and it has the potential to cause not just excessive I/O (as each logical operation causes multiple physical operations) but also large amounts of partial I/O too.
To summarise the summary, emulation mode works all the time, but has the potential to cause partial I/O or misalignment, while native mode guarantees that neither can happen but is not always supported.
Oracle Database 4k Awareness
Oracle introduced 4k awareness as a new feature in Oracle Database 11g Release 2, meaning that from this version of Oracle you should be able to use native mode to store you database. If you are reading this page, you probably know that things are never that simple – in fact there are certain entities in Oracle that work with native mode, while others do not. Since emulation mode is designed for backwards compatibility, all versions of Oracle (and all Oracle file types) work on emulation mode – but some incur the penalties of partial I/O. We are now going to go through the various Oracle file types and look at which may cause problems, as well as consider what can be done to mitigate them.
Oracle Datafiles, Control Files and Redo Logs
Most Oracle I/O is performed to database datafiles (and I guess we can include tempfiles in this group for now). Oracle has its own concept of the smallest unit of work, which is called the data block. The size of a block is defined by the parameter DB_BLOCK_SIZE and will usually be configured to one of a range of sizes: 2k, 4k, 8k (the default), 16k or 32k. It should be obvious that for storage with a 4k physical block size, choosing a blocksize of 2k would be inadvisable and cause considerable wasted effort. However, the choice of a blocksize greater than or equal to 4k will inherently cause I/Os to datafiles of an acceptable size, avoiding the possibility of partial I/O.
However, not all Oracle files are written in these blocks. The controlfile for one has a different blocksize:
SQL> select cfbsz from x$kcccf;
CFBSZ
----------
16384
16384
Luckily this is 16k (and it is always 16k), so as a multiple of 4k we do not have a problem. Where we do have a problem is the online redo logs:
SQL> select lebsz from x$kccle;
LEBSZ
----------
512
512
512
As you can see, these logs default to 512 bytes. Given how frequently the log writer flushes the log buffer to disk (at least every three seconds but much more on a busy system) there is a potential issue here. The new feature introduced from 11.2.0.1 is the ability to change this block size by the use of the BLOCKSIZE keyword when creating redo logs (as well as a blocksize column on v$log):
SQL> ALTER DATABASE orcl ADD LOGFILE
2 GROUP 4 ('/orcl/redo04a.log','/orcl/redo04b.log')
3 SIZE 50M BLOCKSIZE 4k;
The use of 4k redo logs can provide a significant improvement to performance when using a storage system with physical blocks that are 4k in size. But before we dig any deeper into that, we need to look at ASM.
Piggyback Commits – A Diversion

It is briefly worth mentioning that a busy Oracle database (i.e. one performing many transactions per second) will usually perform writes to the online redo logs with I/O sizes that are larger than 512 bytes. The reason for this is that Oracle uses a mechanism for writing redo which is commonly known as the piggyback commit. This is essentially a method of queuing processes that want to commit so that they form a queue which is two levels deep but infinitely wide. Consider a door to a room which remains shut. Users who want to perform a commit (i.e. make their transactions permanent) must form a queue outside the door until it is opened by the log writer process (LGWR). When LGWR is ready, the door opens and everyone in the queue enters the room, at which point the door shuts. LGWR must now write all of the commit data for this room full of users into the online redo log, which it does in one large, sequential write I/O. Meanwhile, during this activity, more users line up outside the door waiting until it opens again.
Why do we care about this? Well, because the result of this queuing method is that, as a database gets busier, the size of the redo writes tend to increase. This is one of the reasons that many high-end TPC benchmark tests actually keep Oracle online redo logs located on disk; disk has serious problems with random I/O but is fairly efficient at performing large, sequential I/Os such as these. See here for more thoughts on this topic.
Oracle ASM 4k Awareness
Another relevant addition to the 11gR2 code is the ability to create ASM diskgroups with a sector size of 4k. Oracle ASM is recommended when running Oracle on high-performance storage such as Violin Memory arrays because ASM allows for raw performance (i.e. there is no filesystem overhead).
To create an ASM diskgroup with a 4k sector size, use the following new disk group attributes (compatibility has to be set to 11.2 or above):
SQL> CREATE DISKGROUP DATA
2 EXTERNAL REDUNDANCY
3 DISK '/path/disk1','/path/disk2','/path/disk3'
4 ATTRIBUTE
5 'au_size'='64M',
6 'sector_size'='4096',
7 'compatible.asm' = '11.2',
8 'compatible.rdbms' = '11.2';
Of course, if the underlying storage devices (e.g. /path/disk1 in the above example) are presented using 4k native mode, there is actually no requirement to use the SECTOR_SIZE clause, since Oracle will automatically pick it up based on information provided by operating system calls (to ioctl), such as those seen when using strace on a create diskgroup statement in ASM:
20531 mmap(NULL, 266240, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f7581ed4000
20531 stat("/dev/mapper/violin_data1", {st_mode=S_IFBLK|0660, st_rdev=makedev(252, 5), ...}) = 0
20531 stat("/dev/mapper/violin_data1", {st_mode=S_IFBLK|0660, st_rdev=makedev(252, 5), ...}) = 0
20531 access("/dev/mapper/violin_data1", R_OK|W_OK) = 0
20531 stat("/dev/mapper/violin_data1", {st_mode=S_IFBLK|0660, st_rdev=makedev(252, 5), ...}) = 0
20531 open("/dev/mapper/violin_data1", O_RDONLY) = 17
20531 ioctl(17, BLKGETSIZE64, 0x7fff002f23d8) = 0
20531 read(17, ""..., 8704) = 8704
20531 ioctl(17, SG_IO, {'S', SG_DXFER_FROM_DEV, cmd[6]=[12, 00, 00, 00, 60, 00], mx_sb_len=32, iovec_count=0, dxfer_len=96, timeout=200, flags=0, data[96]=["\6\22?\10\20\2VIOLIN SAN ARRAY "...], status=00, masked_status=00, sb[0]=[], host_status=0, driver_status=0, resid=28, duration=0, info=0}) = 0
20531 close(17) = 0
20531 stat("/dev/mapper/violin_data1", {st_mode=S_IFBLK|0660, st_rdev=makedev(252, 5), ...}) = 0
20531 open("/dev/mapper/violin_data1", O_RDONLY) = 17
20531 ioctl(17, BLKSSZGET, 0x7fff002edd20) = 0
20531 close(17)
Diversion: The first call highlighted in red, to ioctl(BLKGETSIZE64) is of special note, because this is a new option added to the ioctl function to support 4k devices, i.e. storage presented in native mode. The previous version of this, which still exists in ioctl, is the BLKGETSIZE option. BLKGETSIZE finds the size of the device in multiples of 512 byte blocks, but it returns its answer in the form of an unsigned long. The restrictive size of this datatype means that the call may fail if the device is greater than 2TB in size. In contrast, BLKGETSIZE64 returns a 64 bit type, which overcomes this restriction. This is just one example of how code at varying levels in the stack must be (re)written to support Advanced Format devices in native mode. The second call highlighted in red, incidentally, is the one that queries the device to find the logical block size, which will be 4096 for native mode, or 512 bytes for either emulation mode or pre-Advanced Format devices.
If the storage devices are presented using emulation mode however, Oracle will believe that the device sector size is in fact 512 bytes, therefore denying any attempt to create a diskgroup with SECTOR_SIZE set to 4096. This is not a problem, because if the devices are presented using emulation mode, Oracle will simply create them with a SECTOR_SIZE of 512 bytes. It could be tempting to assume that this might cause performance issues, that ASM will start issuing partial reads and writes in block sizes of 512 bytes, but it doesn’t.

Why? Well mainly because ASM doesn’t really perform much I/O. Don’t forget that ASM is not in the I/O path for a database – it simply manages ASM extent locations and passes the addresses to each client database instance so that they can perform I/O direct to storage. Ok so occasionally ASM will perform its own I/O operations like diskgroup creation or rebalances, but these tend to involve large, multi-block I/Os and so do not cause partials. And ASM’s own metadata, which it stores at the start of each ASM disk, actually uses a 4096 byte blocksize regardless of the underlying sector size… This can be seen in the column BLOCK_SIZE of the dynamic view v$asm_diskgroup.
To summarise the situation with ASM, a diskgroup will pick up the sector size from whatever LUNs it is using as ASM disks. Specifically, it will query the operating system to find the logical block size of those devices and use that. However, in a configuration where Oracle’s ASMLib Linux kernel library is in use, there is an extra layer between ASM and the operating system – and that needs to be investigated next.
Partition Alignment
Here’s a bit of advice I generally offer people about partitioning LUNs prior to allocating them to ASM:
Don’t do it.
Seriously, don’t do it. It’s completely unnecessary , but it’s also the major source of misalignment issues. Quite simply, if you use unpartitioned devices with ASM, everything will be aligned. As soon as you start messing around with partitions, things go wrong.
The reason is that historically many operating systems started partitions at logical block address 63. If the logical blocks are 512 bytes and there are 63 of them, it’s obvious that the partition will not begin at the boundary of the underlying 4k physical blocks. I could write quite a lot on this subject, but this article by Thomas Krenn already covers the subject perfectly, so I will simply state the following golden rules:
- Don’t use partitions for ASM
- If you really must use partitions, ensure they start on the boundary of a 4k physical block
- But seriously, don’t
Creating 4k Database Redo Logs
So we now know that our ASM diskgroups will always have sector sizes based on the underlying storage. ASMLib can influence this, but in general it makes sense not to allow that to happen. Thus if you present storage configured in 512e emulation mode, your diskgroups will have a SECTOR_SIZE of 512. If you present storage configured in 4k native mode, your diskgroups will have a SECTOR_SIZE of 4096.
So what about those pesky database online redo logs that we discussed previously? What happens to them? And do we care?
In the majority of cases the answer here is yes. If the database in question generates a reasonable amount of redo, it will be beneficial to create the redo logs with a 4k block size. If the underlying ASM diskgroup already has a SECTOR_SIZE of 4096, this will happen automatically with no user intervention required; simply query the BLOCKSIZE column of the v$log dynamic view and look for the value of 4096. On the other hand, if the underlying diskgroup has a SECTOR_SIZE of 512 then redo logs will be created with a blocksize of 512 by default, so we need to change that.
As a reminder, from Oracle 11g Release 2 a new BLOCKSIZE clause was added to the redo log creation statement which allowed the argument 4096 or 4k. Let’s try that on a diskgroup with a sector size of 512 and see what happens:
SQL> ALTER DATABASE orcl ADD LOGFILE GROUP 4 ('+DATA') SIZE 50M BLOCKSIZE 4k;
*
ERROR at line 1:
ORA-01378: The logical block size (4096) of file +DATA is not compatible with the disk sector size (media sector size is 512 and host sector size is 512)
Why is this happening? It happens because, as part of the call to create the online redo log files, Oracle spots that the requested blocksize of 4k does not match the diskgroup sector size of 512 bytes, so issues an error. On the face of it, that seems sensible… yet we know that performance is much better if we can set the redo logs to use 4k. If only there was a way to override that check?
Setting The _DISK_SECTOR_SIZE_OVERRIDE Parameter
Luckily there is a way of overriding the sector size check – an underscore parameter called _disk_sector_size_override, which has to be set to true. This parameter is dynamic and should be set in the RDBMS instance:
SQL> alter system set "_disk_sector_size_override"=TRUE scope=both;
I’ve seen a lot of bogus information about this parameter. The most enduring myth is that it in some way has to be set in order to get a performance boost out of solid state disks or flash memory. However the truth is that it has no performance impact, it simply overrides the call by Oracle to the operating system or ASM to find out what sector size is being used by the underlying storage devices or disk group. If you were running a 2.6.32 or higher kernel and created the LUNs as having a 4096 byte blocksize you would not need to set it.

Another oft-mentioned story about this parameter is that it might in some way cause corruption. That’s not the sort of thing people take lightly – and rightly so – but I think this mainly comes from people reading and misunderstanding My Oracle Support note 1500460.1. In this note, the parameter is set in the ASM instance, rather than the database instance; this allows the SECTOR_SIZE of the ASM diskgroup to be overridden. Although the parameter has the same name (and essentially the same function), the consequences of setting it in the database or the ASM instance are very different – and (at least to me) unknown. Let me be clear: do not set it in the ASM instance unless you are told to by Oracle Support. I’m not trying to be alarmist – but there is no reason to set it in ASM in order to get good performance from Advanced Format storage. Here be dragons.
It’s possible that the last paragraph may have alarmed you, as it contained among other things the words “corruption”, “unknown”, and “dragons”. Do not be alarmed if all you plan to do is follow the advice here and set the parameter in the database instance. Oracle’s own FAQ for flash storage with ASM tells you it can be set safely on the database:
FAQ: Flash Storage with ASM (Doc ID 1626228.1)
On top of that, this support note confirms that the parameter is safe to set in this scenario, as well as describing at a high level many of the topics I am discussing here in detail. In fact, the language is almost identical to mine, which isn’t a surprise because the support note was actually written by me.
Using 4k Redo Logs on Flash and SSD-based Storage (Doc ID 1681266.1)
As always with underscore parameters you should seek approval from Oracle Support (point them at this document to save time). Of course, if you really don’t want to set an underscore parameter, you don’t have to. This is only required if you are using the emulation mode configuration. If you use the native mode option, the redo logs will be 4k by default and no underscore parameter is necessary.
The SPFILE Problem
On the subject of the native mode configuration (i.e. the one where everything resides on devices with a 4k logical block size), we have a database blocksize that is 4k or a multiple thereof, controlfiles that are 16k, online redo logs that we can set to use 4k blocksize and ASM diskgroups that understand the 4k-nature of the underlying disks… so everything is perfectly setup to run, right?
SQL> create spfile='+DATA' from pfile;
ORA-01078: failure in processing system parameters
ORA-15081: failed to submit an I/O operation to a disk
ORA-27091: unable to queue I/O
ORA-17507: I/O request size 512 is not a multiple of logical block size
Er no. It seems that Oracle haven’t yet successfully included the functionality that enables a server parameter file (SPFILE) to reside inside a 4k diskgoup. There are two solutions to this issue (or three, depending on your point of view): the first is to keep your SPFILE in a filesystem instead of within an ASM diskgroup – relatively familiar to anyone who remembers the days before ASM, but potentially an issue if you are building a cluster and want the SPFILE shared (unless you have a clustered filesystem available to put it on…). The second is to create a small 512-byte ASM diskgroup just for storing your SPFILE. This is in fact a common solution – with the diskgroup in question typically being called +SYSTEMDG.
The third, of course, is to use the emulation mode configuration instead (as set the underscore parameter).
Incidentally, that error message above is not the only one you might see if you create an SPFILE in a 4k location. You might, perhaps, see this one:
SQL> create spfile='+DATA' from pfile='/home/oracle/orcl.ora';
create spfile='+DATA' from pfile='/home/oracle/orcl.ora'
*
ERROR at line 1:
ORA-00349: failure obtaining block size for '+DATA'
Alternatively, you might be running DBCA in which case you could get this in 11.2.0.3:

PRCR-1079 : Failed to start resource ora.orcl.db
CRS-5017: The resource action "ora.orcl.db start" encountered the following error:
ORA-01078: failure in processing system parameters
ORA-15081: failed to submit an I/O operation to a disk
ORA-27091: unable to queue I/O
ORA-17507: I/O request size 512 is not a multiple of logical block size
ORA-06512: at line 4
. For details refer to "(:CLSN00107:)" in "/home/OracleHome/product/11.2.0/grid/log/half-server4/agent/ohasd/oraagent_oracle/oraagent_oracle.log".
I’ve included them all here so that Google can index them and maybe some unfortunately soul will find the answer to a problem that’s been baffling them: don’t put the SPFILE on a native mode 4k device.
SPFILE Update: Feb 2014
Finally, after considerable time, Oracle has (sort of) fixed the problem of SPFILEs being incompatible with 4k devices. The issues is logged in the following Oracle bug case:
Bug 14626924 – Not able to read spfile from ASM diskgroup and disk with sector size of 4096
According to the information shown on My Oracle Support at the time of writing, the issue is fixed in 11.20.4 as well as the 12.2 code base. Additional details can be found in this blog post entitled Oracle Fixes The 4k SPFILE Problem…But It’s Still Broken. Suffice to say, it still doesn’t work. But the 512e +SYSTEMDG solution means this isn’t an issue anyway.
OCR and Voting Disks
If you are installing Oracle Grid Infrastructure for a Cluster then one of the initial requirements is to choose where to locate the Oracle Cluster Registry (OCR) and Voting Disks. At the moment, at least in 11.2.0.3, putting them on a native mode 4k device will lead to failure:
Creating OCR keys for user 'root', privgrp 'root'..
Operation successful.
Failed to create voting files on disk group DATA.
Change to configuration failed, but was successfully rolled back.
CRS-4000: Command Replace failed, or completed with errors.
Voting file add failed
Failed to add voting disks at /u01/app/11.2.0/grid/crs/install/crsconfig_lib.pm line 6780.
It’s hard to find any better error message than that. Using 11.2.0.3 I have been able to successfully move the OCR onto a 4k device on its own, but the voting disk fails when it is moved manually, with this message in the ASM instance’s alert log:
NOTE: Voting File refresh pending for group 2/0x4efee8de (DATA)
NOTE: Attempting voting file creation in diskgroup DATA
ERROR: Could not create voting files. It spans across 161 AUs (max supported is 64 AUs)
ERROR: Voting file allocation failed for group DATA
And this in a trace file:
2014-04-07 16:28:14.285: [ CSSCLNT]clsssVoteDiskFormat: call clsscfgfmtbegin with leasedata (nil), size 0
2014-04-07 16:28:14.288: [ CSSCLNT]clsssVoteDiskFormat: succ-ly format the Voting Disk
ORA-15303: Voting files could not be created in diskgroup DATA due to small Allocation Unit size
Searching Oracle’s knowledge base for these messages just brings back the usual nonsense support notes about SAN firmware upgrades and the inability of 10g to work with non 512-byte blocksizes, but nothing specific to voting disks and 4k. The only additional trace file data I’ve found has been this:
Trace file /u01/app/oracle/oradiag_root/diag/clients/user_root/host_424699706_80/trace/ora_3695_140493881972512.trc
KGFCHECK kgfnStmtExecute01c: ret == OCI_SUCCESS: FAILED at kgfn.c:1562
It’s not ideal. But since it’s already essential to place the ASM instance’s SPFILE in a 512e emulation mode diskgroup (which we call +SYSTEMDG), it makes sense to put the OCR and voting disks in here too, thus avoiding the problem.
Linux 4k Awareness
Now it isn’t just Oracle that you need to consider when you use 4k sector storage devices. The operating system is also a potential candidate for 4k ignorance. A discussion of the huge ugly problem faced by the Linux kernel developers is available here and gives a much better description than I can manage, but the watershed moment for the Linux kernel came in release 2.6.31 with the following changes to the SCSI layer:
sd: Detect non-rotational devices (commit), physical block size and alignment support (commit)
The critical inclusion there is the ability to detect physical block size, which is another way of saying that from 2.6.31 the kernel actually understood that logical and physical block size could differ. Look at this snippet from the commit differences of the Linux SCSI driver:
@@ -1521,11 +1533,17 @@ got_data:
string_get_size(sz, STRING_UNITS_10, cap_str_10,
sizeof(cap_str_10));
- if (sdkp->first_scan || old_capacity != sdkp->capacity)
+ if (sdkp->first_scan || old_capacity != sdkp->capacity) {
sd_printk(KERN_NOTICE, sdkp,
- "%llu %d-byte hardware sectors: (%s/%s)\n",
+ "%llu %d-byte logical blocks: (%s/%s)\n",
(unsigned long long)sdkp->capacity,
sector_size, cap_str_10, cap_str_2);
+
+ if (sdkp->hw_sector_size != sector_size)
+ sd_printk(KERN_NOTICE, sdkp,
+ "%u-byte physical blocks\n",
+ sdkp->hw_sector_size);
You don’t need to understand C programming to see what’s happening here; the lines in red have been removed and the lines in green have been added. You can see that, in red, the kernel used to report something called “hardware sectors”, but now (in green) it reports this metric as “logical blocks” while separately reporting a new metric called “physical blocks”.
Production Linux kernels prior to 2.6.31 simply do not understand native mode 4k devices, which means LUNs presented to them must use 512e emulation mode. So the 2.6.18 kernel for example is not able to support 4k sector drives – that means all Red Hat Enterprise Linux 5 distributions, all Oracle Enterprise Linux 5 distros using the RHEL-compatible kernel, SUSE Linux Enterprise Server 10 etc.
There is a very simple way to determine if your kernel understands the concept of logical versus physical devices: the SYSFS filesystem. The 2.6.31 kernel, as well as later versions, has a new SYSFS flags (in the directory /sys/block/<device>/queue) to show information such as the physical and logical block sizes. It also contains a new flag called rotational which shows whether a block device relates to rotational media or not (so you would see a zero for flash):
[root@half-server4 ~]# cd /sys/block/sdc/queue
[root@half-server4 queue]# ls -l logical_block_size physical_block_size rotational
-r--r--r-- 1 root root 4096 Apr 3 16:02 logical_block_size
-r--r--r-- 1 root root 4096 Apr 3 16:02 physical_block_size
-rw-r--r-- 1 root root 4096 Apr 3 16:02 rotational
[root@half-server4 queue]# cat logical_block_size
4096
[root@half-server4 queue]# cat physical_block_size
4096
[root@half-server4 queue]# cat rotational
0
The root user can also write a 1 or 0 to the rotational flag to change its value; you can read some more about it here.
Oracle on 4k with Filesystems: Problems with DIRECTIO
So far I’ve only discussed the use of Oracle with ASM on 4k devices. However, there are still some people out there who prefer to put their databases on filesystems (the crazy ones) or who have no choice through decisions made beyond their control (the unfortunate ones). If you belong to one of these groups, the headline news for you is this: don’t bother with native mode. It’s not that it doesn’t work, because it does… but the problem is that it cannot coexist with direct I/O.
Direct I/O is the ability for applications (such as the Oracle database) to perform I/O operations which bypass the Linux filesystem read and write caches (in a similar way to how direct path I/O in Oracle bypasses the database buffer cache). Many members of the Linux community have commented that the implementation of direct I/O in Linux is problematic, including Linus Torvalds himself. Oracle discusses direct I/O here; its use with the database is controlled by the parameter FILESYSTEMIO_OPTIONS (a setting of DIRECTIO or SETALL means it is enabled).
If you build a database on a 4k filesystem such as ext3 and then attempt to enable direct I/O, you will see messages that look something like this:
ORA-00210: cannot open the specified control file
ORA-00202: control file: '/fstest/fs4ktest/oracle/oradata/FSTEST/controlfile/o1_mf_9k9wzp31_.ctl'
ORA-27047: unable to read the header block of file
Linux-x86_64 Error: 22: Invalid argument
Additional information: 1
ORA-205 signalled during: ALTER DATABASE MOUNT...
I’m not going to cover this further here, because I already blogged about this in another article here. What I will do though is steal my own words from that article and put them right here:
The answer, which you can find in My Oracle Support note 1133713.1, is that Oracle does not support 4k devices with direct I/O. This has been the case for a long time – I remember first discovering this nearly two years ago, on 11.2.0.2, yet there is no sign of it being fixed. According to the note, “It is not yet known in which version this support will be available.” Pah.
Incidentally, Oracle ASM uses unbuffered I/O by design – it cannot be disabled – which makes things interesting, because as we’ve just seen direct I/O and native mode 4k support do not play well together… which is where ASMLib comes into the equation. But first, a summary.
Summary
The operating system always has its say. You may be running the very latest Oracle software which is fully compliant with 4k (although I have yet to find a version that is) but if the operating system – and specifically the kernel – are not 4k aware, you will get nowhere. Look for kernels of 2.6.32 or later, otherwise native mode is not possible and emulation mode becomes the only choice.
If you are using emulation mode, avoid (or at least be extremely wary of) partitions, as they will cause terrible misalignment issues. Don’t underestimate this! Partitions are rarely beneficial and often detrimental to your configuration.
The Oracle ASMLib Kernel Module
Oracle ASMLib is an open source kernel library which Oracle contributes to Linux. Back in the days when Oracle did not have it’s own kernel, it supplied and supported ASMLib for Red Hat, essentially doing all the work for Red Hat to compile and test the module for their kernel. Novell (supplier of SUSE Linux) had to do this work itself, so it took the source code from Oracle and produced the kernel module which can be found in the SUSE distributions.
At the point when Red Hat 6 came out, Oracle (having become frustrated with Red Hat) made the decision to introduce it’s own kernel, the Unbreakable Enterprise Kernel. One of the consequences of this was that Oracle no longer did the work on behalf of Red Hat to produce ASMLib, so for a while it was not possible to use it on Red Hat 6 at all. Eventually Red Hat made the decision to produce an RH6-compatible version of ASMLib itself, which is known as kmod-oracleasm. However, the standoff still continues in some sense, because Red Hat currently states that this module is “is provided for the convenience of our customers but is not supported”. Novell, to its credit, continues to include ASMLib in the SUSE kernel and does not appear to make any of these customer-inconveniencing claims regarding support.
ASMLib and 4k
Oracle preaches the virtues of ASMLib as being good for device management and delivering a reduction in system resource consumption. To this I would add another benefit: it is the only tool that allows Oracle ASM to use native mode 4k devices in Linux.
Yes, you read that correctly. If you want to use native mode for your ASM disk devices then you must use ASMLib. ASM does not work without it. This appears to be due to the same problems with direct I/O discussed above. Non-ASMLib configurations of ASM attempt to send I/O through normal Linux I/O functions to 4k devices, but with the O_DIRECT flag set – and the outcome is failure. ASMLib uses a different I/O path which is successful.
SQL> CREATE DISKGROUP DATA4096 EXTERNAL REDUNDANCY
2 DISK '/dev/sdc'
3 ATTRIBUTE
4 'sector_size'='4096',
5 'compatible.asm' = '11.2',
6 'compatible.rdbms' = '11.2';
CREATE DISKGROUP DATA_4096 EXTERNAL REDUNDANCY
*
ERROR at line 1:
ORA-15018: diskgroup cannot be created
ORA-15080: synchronous I/O operation to a disk failed
From the alert log we see:
ORA-27061: waiting for async I/Os failed
WARNING: IO Failed. group:0 disk(number.incarnation):2.0xe9527fe0 disk_path:/dev/sdc
AU:0 disk_offset(bytes):0 io_size:4096 operation:Read type:asynchronous
result:I/O error process_id:16683
Whatever the reason, ASMLib is essential if using native mode.
Partial and Misaligned I/O with ASMLib
And now for some good news. If you use ASMLib with native mode, obviously there are no partial or misalignment issues because native mode stops that happening. But ASMLib also appears to remove any issues relating to partials or misalignment when using emulation mode. I’ve tested this in numerous different configurations and I simply do not see anything sub-4k or misaligned (assuming the redo logs are configured to be 4k of course). On the other hand, when using emulation mode without ASMLib, I see plenty of problematic I/O operations, especially during operations such as ASM rebalances. It appears, although I do not have proof, as if any attempt to access an ASM extent that was previously unused results in some sort of fracturing of I/O.
Whatever the reason, ASMLib appears essential if using emulation mode.
The ORACLEASM_USE_LOGICAL_BLOCK_SIZE Parameter
In more recent versions of ASMLib, Oracle introduced a new parameter into the /etc/sysconfig/oracleasm file:
[root@half-server4 mapper]# tail -5 /etc/sysconfig/oracleasm
# ORACLEASM_USE_LOGICAL_BLOCK_SIZE: 'true' means use the logical block size
# reported by the underlying disk instead of the physical. The default
# is 'false'
ORACLEASM_USE_LOGICAL_BLOCK_SIZE=false
It can be changed by editing the configuration file, or more preferably by running the configure command with either the -b (use logical block size) or -p (use physical blocksize) options, as shown here:
[root@half-server4 ~]# oracleasm configure -b
Writing Oracle ASM library driver configuration: done
[root@half-server4 ~]# oracleasm configure | grep ORACLEASM_USE_LOGICAL_BLOCK_SIZE
ORACLEASM_USE_LOGICAL_BLOCK_SIZE="true"
[root@half-server4 ~]# oracleasm configure -p
Writing Oracle ASM library driver configuration: done
[root@half-server4 ~]# oracleasm configure | grep ORACLEASM_USE_LOGICAL_BLOCK_SIZE
ORACLEASM_USE_LOGICAL_BLOCK_SIZE="false"
The outcome is simple: if the parameter is set to false (the default – which is a strange choice in my opinion) then ASMLib will pick up the physical block size of the device and present that to ASM. Since the physical block size of an Advanced Format device is always 4k this essentially stops emulation mode from having any effect: all devices look like they are using native mode.
If the parameter is set to true (lower case!) then ASMLib will pick up the logical block size, which is reflects whether the device is using native mode or emulation mode. Given that you can never store, for example, an Oracle SPFILE on a 4k device, it makes zero sense to have this parameter set to the default of false. The recommendation here is therefore to set it to true – but be aware that it will affect any existing devices you have. Note also that the driver has to be restarted before the change is picked up.
More Oracle 4k Madness
That isn’t the end of the story with Oracle’s 4k support, there are other articles detailing more quirks of behaviour:
Oracle Fixes The 4k SPFILE Problem…But It’s Still Broken: testing the patch for the SPFILE problem and finding it still exists
More Problems with Oracle’s Support of 4k Devices: problems with using 4k filesystems for databases and diagnostic destinations.

Of course, my advice is for educational purposes only and you should thoroughly test anything you do before putting it into production. Also, I am duty-bound to say that you should seek permission from Oracle Support before setting any underscore parameters … but then you knew that, right?

Thank you very much for the great post. In my case the physical and logical block size is 512. Where as I am using ASM, we are seeing log file sync sporadically sometimes went upto 10 seconds!!..also from the LGWR trace file we are seeing varying runtimes based on the size to be written.
We are thinking to create a disk group of sector size 4K and use 512e mode then create the redo log block size of 4K instead of current 512. Let me know your thoughts.
Also it would be great if you have comparison on the performance benefits between different settings.
I’m missing a vital piece of information here: what is your storage? Is it flash-based? If it’s advertising itself as 512:512 then it seems unlikely that this is going to be the problem. You say that you see log file sync times varying, but this wait event is not the one which will tell you if the issue is I/O related – you need to check the values of log file parallel write (LFPW). In particular, check the wait event histogram for LFPW.
My buddy Kevin wrote an amazing article on log file sync which is still relevant today. You should read it. In essence, much of the time spent waiting on log file sync can be attributed to CPU scheduling issues rather than write I/O. Check the value of LFPW and if it is not showing the same variation you need to investigate other avenues. You can also disable redo logging (on a test system only, never on production!) to categorically confirm or refute whether write I/O is the issue.
Here is the link to Kevin’s article:
It’s also worth knowing that in later versions of 11gR2 and beyond, a feature called Adaptive Log File Sync means the log writer can switch to a new mode called “polling” which can alleviate some of the issues seen with log file sync on busy platforms. You should read Frits’ excellent posts on the subject – start here:
Hi, great article.
How would you comment this:
“Oracle recommends that you create a single whole-disk partition on each disk.”
https://docs.oracle.com/database/121/CWLIN/manpreins.htm#CWLIN408
You are saying we don’t need partitions on LUNs and we shouldn’t do it but do you refere to 4K devices only or in general?
Regards
There are two cases.
In the case where you are using Advanced Format 4Kn storage with a 4096 byte sector size, partitions are actively bad. This is because the default partition size does not align to 4k and therefore causes misaligned I/O.
In the case where you are using “normal” storage, i.e. anything where 4k alignment is not an issue, there is no technical reason why you should create a partition before using ASM. Oracle recommends as best practice that you use a partition simply because they feel it will make it less likely for an administrator to look at the LUN and say, “Hey that one hasn’t got a partition on it – I’ll destroy it without first checking to see if it’s critical to anything”. This is clearly nonsense, but who cares – it’s only a recommendation, right?
Unfortunately, whoever wrote the ASMLib createdisk routine got a bit carried away and actually inserted a check which will not allow an ASBLib stamp to be placed on an unpartitioned device. This is a whole different level of annoying on Oracle’s part, but it can at least be overridden by directly calling the asmtool function. More importantly, for multipath devices (and let’s face it, you should ALWAYS be using multipathing for production databases) it cannot easily tell if the partition exists, so you can ignore the “requirement” anyway.
So to summarise, I’m not saying that you shouldn’t partition your devices for ASM. I won’t be doing it… ever. But there’s no technical reason why you should or shouldn’t, other than in the case where you use 4k storage. I just don’t like being forced to do something that is utterly unnecessary and pointless.
Thank you for this great explanation. I hate ASMlib to be frank and prefer multipathing and udev instead, as I had many severe problems in 10g R2
If you are not an expert in the field it is sometimes impossible to get the reasoning from official docs on some of the Oracle’s official recommendation. Internals are well hidden in general and for ordinary DBA it is better to follow the recommendation to avoid formal risk.
Thank you for enlightening me, I will consider not using partitions next time.
Regards
Hi,
I beg to differ about the needs of a partition for ASM disks.
S.O. kernels read the first sector of the disk in order to understand how partitions were created.
If there is anything written in the partition table location, and the kernel find it to be a corrupt partition (for example, if it goes beyond the size of the disk), it won’t make this disk available at all.
I would recommend to always create a partition. Most user land partition programs will auto-align the partition nowadays.
Best regards,
Hi flashdba,
Great column. Regarding your advice not to partition devices for use with ASM, this agrees with my own experience. I simply use multipathing and udev rules and do not create a partition table and this is much easier than using asmlib. But there does seem to be a widespread belief that devices must be partitioned before ASM can use them, and then you need to go through partition alignment, which can be a pain when you have numerous devices. There are many blogs and manuals that say this. My question is, where did the idea come from? Is this because of asmlib, or was there a time when ASM did require devices to be partitioned?
thanks,
Hi. I asked the ASM Development Team this question once – I was with Rich Long (a VP of Engineering at Oracle) and his team. They told me that the reason for insisting on partitions was not technical, it was simply that they had experienced too many storage administrators looking at unpartitioned LUNs and deciding that they were unused and could therefore be repurposed. Cue ASM Disks suddenly vanishing and therefore data loss.
However, I do not like being forced to use a partition for no valid reason. The above issues should be solved by good configuration management and change control processes. Meanwhile, the mandate of partitions actually causes plenty of issues on, for example, Advanced Format storage devices where the result is non-alignment of block boundaries.
The ASMLib kernel library actually checks for the existence of a partition on SCSI devices when the createdisk command is invoked – and fails with an error if the partition is missing. However, most enterprise deployments make use of multipathing – and ASMLib cannot perform the same check on a multipath device, so is ignorant of whether the partition is present or not.
ASMLib can also be overruled with the asmtool command, as shown half way down in the following post:
This does shed some light on the subject. Thanks so much.
Great article, like all the others that I have gone through so far. I find your site is very similar to the likes of Kevin Closson, Jonathan, etc., in that it is very technical but the explanation is very clear.
I would like to ask a few questions related to the read-modify-write activity and why it is expensive:
(1) Is this activity only related to the 512e mode? What I mean here is that when configured with 4k/native mode, if we update a block, a 4k block would be read, modified and then written back to the flash. To me, this also sounds like a read-modify-write activity?
(2) Is it expensive in the 512e mode because of the overhead required to update only a partial space in the block? If yes then can you elaborate a bit where that overhead comes from.
Thank you. Kevin and Jonathan set a very high bar for quality of work, so that is truly a compliment.
In this case, the read-modify-write activity is only related to situations where the write IO call issued by the operating system (and whatever is above it, e.g. the database) is smaller than the minimum supported IO size on the storage platform.
So in the case of 512e, the OS is allowed to issue a write of size 512 bytes (or any multiple of 512 below 4096) because the storage array advertises a logical blocksize of 512 bytes. However, since the physical blocksize of the array is 4096 bytes, each 512 byte write request causes the array to read 4096 bytes, modify the requested 512 bytes and then write down the 4096 bytes again. The amount of write bandwidth the database or OS thinks it is creating is actually 4 x greater. Even running utilities like iostat on the host will not show this, as the write amplification is taking place on the array, so it can be difficult to diagnose why storage performance is terrible for what is apparently a modest workload.
Now, to answer your question about why a 4kN write isn’t a read-modify-write, let’s consider the use case where this issue is at its most impactful: database transaction logs. An Oracle redo log has a default block size of 512 bytes, which makes it a major headache for 512e implementations. Consider that you are running a databases and making changes to the data, causing redo information to be written to the redo log buffer. When the buffer is flushed to storage, Oracle wants to write a 512 byte redo block. It doesn’t need to read the original information first, it just wants to update block X to contain the new redo data, but the storage array has to read blocks X+1 through X+7 first, modify block X and then write back blocks X through X+7. On the next flush of the redo log buffer, block X+1 will be amended, but the array has to first read block X and blocks X+2 through X+7, then modify block X+1 before writing all 8 blocks back again. And so on. This is clearly inefficient.
Meanwhile, if you configure Oracle to use a redo blocksize of 4k, the log writer will write down its changes from the redo log buffer as a 4096 byte write. The array does not need to read anything in first, just process the 4k write request. Each IO request from the host corresponds to a single IO request on the array and there is no amplification of writes. In other words, there is no overhead required to translate from logical blocksize to physical blocksize.
Thank you for the clarification. What I assumed was that in the 512e mode, the array would read the entire 4k bytes in one IO for a 512-byte modification request because that is what the physical sector is based on.
And you are correct.
Given that storage arrays have decent amount of DRAM cache sitting on top of disks/flash. Writes are acknowledged as soon as they hit the DRAM. Data is then de-staged to the storage media later based on the algorithms. In this scenario, how much latency would the process writing to the storage see due to the read-modify-write phenomena?
Thanks
This is not necessarily true. Most All Flash Arrays (by which I mean arrays designed from the ground up to use flash, e.g. Kaminario K2, DellECM XtremIO, Pure Storage etc) do not make use of DRAM caches in the same way as legacy-architecture storage arrays originally designed for disk. Where DRAM is used, it is typically in the form of a FIFO buffer which allows multiple host writes to be grouped together into one array write (useful, for example, if the array writes a wide stripe across many SSDs).
This particular page of my blog was written during a period when I worked for Violin Memory, a vendor with a ground-up design AFA which did not use DRAM cache but which did present storage using Advanced Format protocols (with a physical blocksize of 4096 bytes). Therefore the question is not relevant in this case.
In my subsequent time in the flash storage industry, I have not yet run across another AFA product which uses Advanced Format – and in fact, even Violin’s later generation 7000 series arrays switched to advertising the physical blocksize as 512 bytes.
Thank you for the clarification. Can you please point me to where can I find some literature that can explain/summarize the difference between a ground-up AFA and an array like Unity in terms of reading data.
Thanks
I don’t have any content on Unity, but here’s an article I wrote discussing the reasons why a ground up approach is essential for All Flash:
Thank you for a great explanation in your article! It helped me very much as I am going to migrate Oracle 11g ASM database to 4K SSD disks.
Could you please clarify in more detail your recommendation to use 4K redo logs blocksize vs using 512 redo blocksize for ASM with 512e mode on 4K SSD disks. According to my vision of the process of reading/writing data to disks in 512e mode there is no exact correspondence between database block and storage block on the disk. In case when we want to write 4K redo block to the disk in 512e mode we could change 8 different blocks on the disk the same way as we use 512 redo blocksize. 4K disk blocks could be already partly filled by some other processes in 512e mode and we have to use free space in these blocks to write data. The same is happening for reading data by 4K blocks.
Am I wrong in my understanding of block accessing process in 512e mode or maybe SAN has some algorithms recommending it to use only one physical block on the disks when it gets 4K block size requests from OS/App in 512e mode?
If you are creating ASM disks on 512L/4096P storage volumes then (providing you haven’t partitioned them first) you will, by default, get block alignment for all types of Oracle file which have a blocksize of 4k and above. ASM just does this, because of the way it likes to lay everything out inside Allocation Units (which are always multiples of 4K). The exception, of course, is the redo logs – which have a default blocksize of 512 bytes. Thus every redo read or write will incur the penalty of a “partial I/O”.
If, on the other hand, your volumes are partitioned (e.g. a standard Linux partition), all of your Oracle file types will be misaligned, crossing the boundary between different 4096 byte physical blocks. That is why I recommend not to use partitions if your underlying storage volumes are 512L/4096P.
However, none of this is necessary unless your storage really is running in 512e mode. You really must make sure this is the case, because if your storage is just plain old 512L/512P then none of this is worth the effort.
Thank you very much for your answer!
Hi flashdba,
What are your thoughts on this:
12.2.0.1, 2-node cluster on Solaris 11.3 with XtremIO X2 storage. Installation went fine, but ASM instance won’t restart using spfile in ASM disk group. From alert_+ASM1.log:
ORA-00600: internal error code, arguments: [kgfdp_readMeta02], [4096], [8192], [0], [], [], [], [], [], [], [], []
ERROR: Unable to get logical block size for spfile ‘+OCR/cluster1/ASMPARAMETERFILE/registry.253.979932193’.
Opened an SR, support said “OS level disk block size was 8k which is not supported” and points to unpublished bug 21603458:
“During GI installation, hit bug 21316134 on step of ASM configuration.
This issue happened when the volblocksize is set to 8K byte, which is the
default value of ZFS. And it happened on 12.2 only.
Root cause of this issue is that the block size of 512 byte ~ 4K is valid on
12.2, 8K is a misconfiguration.”
Physical block size is indeed 8k:
/usr/sbin/devprop -n /dev/dsk/xyz device-blksize device-pblksize
512 blk
8192 physical
I’m trying to make sense of this. Are we in the same territory as what you talk about in your article? Where is this requirement “block size of 512 byte ~ 4K” coming from?
Thanks.
Yes. It’s true, a physical block size of 8k is absolutely not supported. Whereas a physical block size of 4k is supported but just doesn’t work.
I strongly suggest using a physical block size of 512 bytes to avoid spiraling into madness…
Thanks for your answer. 2 quick questions about “8k is absolutely not supported”:
1. Would there be any official reference supporting this statement (Oracle documentation, MOS note, etc.)? My storage admins will want to see it to believe it and for now create all disks with an 8k block size.
2. This applies only to the disks with the ASM spfile or to all ASM disks?
To be honest, I was unaware that there were options to create 8k physical block size volumes. What’s the motive? Disks have been 512 byte for decades until Advanced Format (4k) was introduced – and that still isn’t properly supported by some vendors, Oracle among them.
1. I know of no documents formally stating this. Sorry.
2. From memory it was the spfile and voting disks that break on 4k. But 8k is so far away from the pack that you would be advised not to make yourself the first one to try it.
Thankk you for writing this
Thank You. Excellent.
Actually was halfway, backed-off. thanks for your trust by not trusting 🙂
An article from eight years ago is still teaching me today. I really enjoyed reading it. Thank you for writing such an insightful piece.”