In the scientific world, theoretical physicists postulate theories and ideas, for example the Higgs Boson. After this, experimental physicists design and implement experiments, such as the Large Hadron Collider, to prove or disprove these theories. In this post I’m going to try and do the same thing with databases, except on a smaller budget, with less glamour and zero chance of winning a Nobel prize. On the plus side though, my power bills will be a lot lower.
That last paragraph was really just a grandiose way of saying that I have an idea, but haven’t yet thought of a way to prove it. I’m open to suggestions, feedback and data which prove or disprove it… but for now let’s just look at the theory.
Visualising Database Server I/O Workload
If you look at a database server running a real life workload, you will generally see a pattern in the behaviour of the I/O. If you plot a graph of the two extremes of purely sequential I/O and purely random I/O most workloads will fit somewhere along this sliding scale :

Now of course workloads change all the time, so this is an approximation or average, but it makes sense. After all, we do this in the world of storage, because if the workload is highly random the storage requirements will be very different to if the workload is highly sequential.
What I am going to do now is plot a graph with this as the horizontal axis. The vertical axis will be an exponential representation of the storage footprint used by the database server, i.e. the amount of space used. I can then plot different database server workloads on the graph to see where they fall.
But first, two clarifications. I am at pains to say “database server” instead of “database” because in many environments there are multiple database instances generating I/O on the same server. What we are interested in here is how the storage system is being driven, not how each individual database is behaving. Remember this point and I’ll come back to it soon. The other clarification is regarding workload – because many systems have different windows where I/O patterns change. The classic (and very common) example is the OLTP database where users log off at the end of the day and then batch jobs are run. Let’s plot the OLTP and batch workloads as separate points on our graph.
Here’s what I expect to see:

There are data points in various places but a correlation is visible which I’ve highlighted with the blue line. Unfortunately this line is nothing new or exciting, it’s just a graphical representation of the fact that large databases tend to perform lots of sequential I/O whereas small databases tend to perform lots of random I/O.
Why is that? Well because in most cases large databases tend to be data warehouses, decision support systems, business intelligence or analytics systems… places where data is bulk loaded through ETL jobs and then scanned to create summary information or spot trends and patterns. Full table scans are the order of the day, hence sequential I/O. On the other hand, smaller databases with lots of random I/O tend to be OLTP-based, highly transactional systems running CRM, ERM or e-Commerce platforms, for example.
Still, it’s a start – and we can visualise this by dividing the graph up into quadrants and calling them zones, like this:
 This is only an approximation, but it does help with visualising the type of I/O workload generated by database servers. However, there are two more quadrants looking conspicuously un-labelled, so let’s now turn our attention to them.
This is only an approximation, but it does help with visualising the type of I/O workload generated by database servers. However, there are two more quadrants looking conspicuously un-labelled, so let’s now turn our attention to them.
Database Consolidation I/O Workload
The bottom left quadrant is not very exciting, because small database systems which generate highly-sequential workloads are rare. I have worked on one or two, but none that I ever felt should actually have been designed to work that way. (One was an indexing system which got scrapped and replaced with Lucene, the other I am still not sure actually existed or if it was just a bad dream that I once had…)
The top right quadrant is much more interesting, because this is the world of database consolidation. I said I would come back to the idea that we are interested not in the workload of the database but of the database server. The reason for this is that as more databases are run on the same server and storage infrastructure, the I/O will usually become increasingly random. If you think about multiple sets of disparate users working on completely different applications and databases, you realise that it quickly becomes impossible to predict any pattern in the behaviour of the I/O. We already know this from the world of VDI, where increasing the number of seats results in an increasingly random I/O requirement.
The top right quadrant requires lots of random I/O and yet is large in capacity. Let’s label it the consolidation zone on our graph:

We now have a graphical representation of three broad areas of I/O workload. If we believe in the trend of database consolidation, as described by the likes of Gartner and IDC, then over time the dots in the DW and OLTP zones will migrate to the consolidation zone. I have already blogged my thoughts on the benefits of database consolidation, bringing with it increased agility and massive savings in operational costs (especially Oracle licenses) – and many of the customers I have been speaking to both at Violin and in my previous role are already on this journey, even if some are still in the planning stages. I therefore expect to see this quadrant become increasingly populated with workloads, particularly as flash storage technologies take away the barriers to entry.
I/O Workload Zone Requirements
The final step in this process is to look at the generic requirements of each of our three workload zones.

The data warehouse zone is relatively straightforward, because what these systems need more than anything is bandwidth. Also known as throughput, this is the ability of the storage to pump large volumes of data in and out. There is competition here, because whilst flash memory systems can offer excellent throughput, so can disk systems. So can Exadata of course, it’s what it was designed for. Mind you, flash should enable a lower operational cost, but this isn’t a sales pitch so let’s move on to the next zone.
The OLTP zone is all about latency. To run a highly-transactional system and get good performance and end-user experience, you need consistently low latency. This is where flash memory excels – and disk sucks. We all (hopefully) know why – disk simply cannot overcome the seek time and rotational latency inherent in its design.
The consolidation zone however is particularly interesting, because it has a subtly different set of requirements. For consolidation you need two things: the ability to offer sustained high levels of IOPS, plus predictable latency. Obviously when I say that I mean predictably low, because predictably high latency isn’t going to cut it (after all, that’s what disk systems deliver). If you are running multiple, disparate applications and databases on the same infrastructure (as is the case with consolidation) it is crucial that each does not affect the performance of the other. One system cannot be allowed to impact the others if it misbehaves.
Now obviously disk isn’t in with a hope here – highly random I/O driving massive and sustained levels of IOPS is the worst nightmare for a disk system. For flash it’s a different story – but it’s not plain sailing. Not every flash vendor can truly sustain their performance levels or keep their latency spike-free. Additionally, not every flash vendor has the full set of enterprise features which allow their products to become a complete tier of storage in a consolidation environment.
As database consolidation increases – and in fact accelerates with the continued onset of virtualisation – these are going to be the requirements which truly differentiate the winners from the contenders in the flash market.
It’s going to be fun…
Disclaimer
 These are my thoughts and ideas – I’m not claiming them as facts. The data here is not real – it is my attempt at visualising my opinions based on experience and interaction with customers. I’m quite happy to argue my points and concede them in the face of contrary evidence. Of course I’d prefer to substantiate them with proof, but until I (or someone else) can devise a way of doing that, this is all I have. Feel free to add your voice one way or the other… and yes, I am aware that I suck at graphics.
These are my thoughts and ideas – I’m not claiming them as facts. The data here is not real – it is my attempt at visualising my opinions based on experience and interaction with customers. I’m quite happy to argue my points and concede them in the face of contrary evidence. Of course I’d prefer to substantiate them with proof, but until I (or someone else) can devise a way of doing that, this is all I have. Feel free to add your voice one way or the other… and yes, I am aware that I suck at graphics.
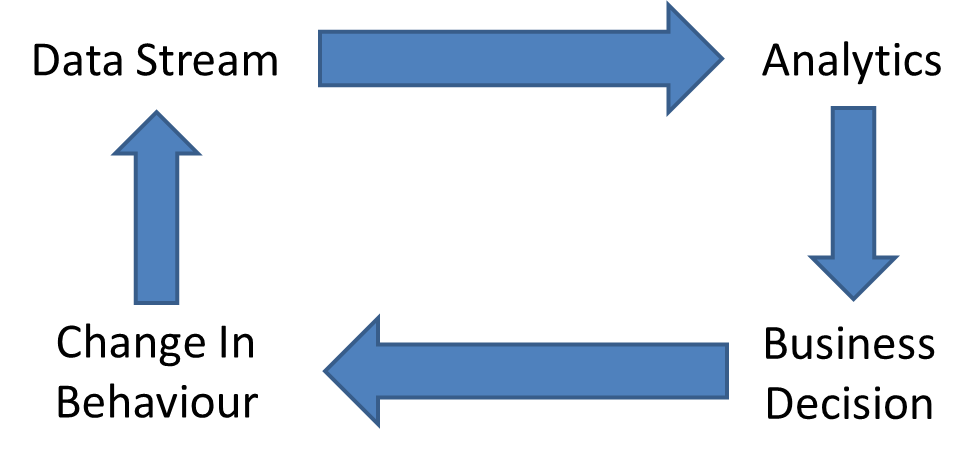
 For some time now I’ve been using the Silly Little Oracle Benchmark (SLOB) tool to drive physical I/O against the various high performance flash memory arrays I have in my lab (one of the benefits of working for Violin Memory is a lab stuffed with flash arrays!)
For some time now I’ve been using the Silly Little Oracle Benchmark (SLOB) tool to drive physical I/O against the various high performance flash memory arrays I have in my lab (one of the benefits of working for Violin Memory is a lab stuffed with flash arrays!) A lot of people I know use
A lot of people I know use 


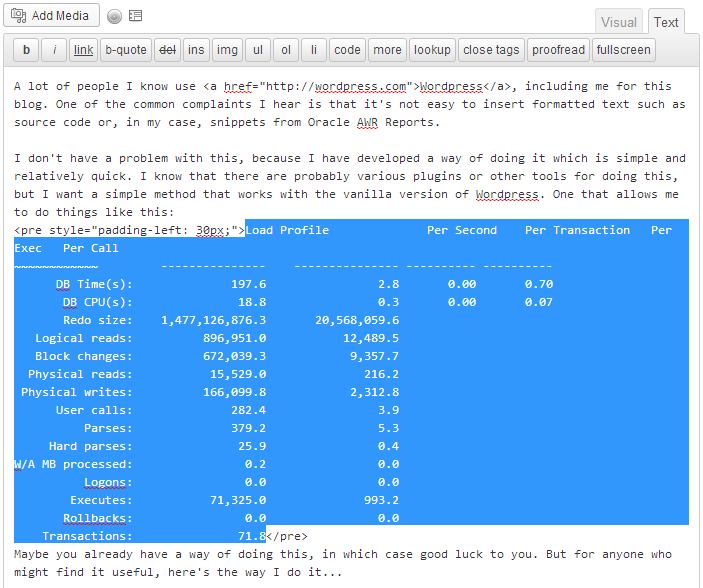









 Key phrase: “
Key phrase: “ Key phrase: “
Key phrase: “ Key phrase: “Legacy approaches are not working”
Key phrase: “Legacy approaches are not working” Key phrase: “An innovative new way of thinking”
Key phrase: “An innovative new way of thinking” Key phrase: “Our unique product / service / solution”
Key phrase: “Our unique product / service / solution”



 I asked how he wanted to run this rig, assuming there were no inhibitors. He wanted most of the memory allocated to Oracle, taking advantage of 11.2.0.3’s features and fixes. OK, then let’s set those and start diagnosing from there; no sense fixing a system running in a config you don’t want—especially since efforts to make the test system look and act like prod only with faster storage had all failed. A quick run through of the report test battery showed results similar to what they’d seen before. We broke it down to the smallest granule we could: run a single report, see the SQL it generates on the test system, compare its explain plan there to what production would do with it. This being my first run-in with
I asked how he wanted to run this rig, assuming there were no inhibitors. He wanted most of the memory allocated to Oracle, taking advantage of 11.2.0.3’s features and fixes. OK, then let’s set those and start diagnosing from there; no sense fixing a system running in a config you don’t want—especially since efforts to make the test system look and act like prod only with faster storage had all failed. A quick run through of the report test battery showed results similar to what they’d seen before. We broke it down to the smallest granule we could: run a single report, see the SQL it generates on the test system, compare its explain plan there to what production would do with it. This being my first run-in with  Sure there’s your PARALLEL_DEGREE_LIMIT, possibly affected by your core count and PARALLEL_THREADS_PER_CPU, and of course your options for PARALLEL_DEGREE_POLICY, plus PARALLEL_MAX_SERVERS which is derived from some unspecified mix of CPU_COUNT, PARALLEL_THREADS_PER_CPU and the PGA_AGGREGATE_TARGET. But have you run DBMS_RESOURCE_MANAGER.CALIBRATE_IO? Have a look over Automatic Degree of Parallelism in 11.2.0.2 [ID 1269321.1] to see if you might be limiting yourself parallel-wise because the database has no idea what your IO subsystem is capable of. Note that they do not mention workload system stats in this context. I couldn’t find verification that these play no part in DOP, but this note seems to suggest the values in DBA_RSRC_IO_CALIBRATE play a much more significant role now. Following a link about a bug (10180307) in 11.2.0.2 and below, older versions of the CALIBRATE_IO procedure could produce unpredictable results. But more important was the comment that “The per process maximum throughput (MAX_PMBPS) value [might be] too large, resulting in a low DOP while running AutoDOP.” We confirmed this by allowing CALIBRATE_IO to run for about 10 minutes and checking the results. What we saw was 31K IOPS, 328 MB/s total, 334 MB/s per process, and a latency of 0. Interesting numbers, but the explain plan still said the computed DOP was 1. So what does Oracle suggest you do if you don’t like the parallelism? Cheat and set the values manually. According to the same note, start with:
Sure there’s your PARALLEL_DEGREE_LIMIT, possibly affected by your core count and PARALLEL_THREADS_PER_CPU, and of course your options for PARALLEL_DEGREE_POLICY, plus PARALLEL_MAX_SERVERS which is derived from some unspecified mix of CPU_COUNT, PARALLEL_THREADS_PER_CPU and the PGA_AGGREGATE_TARGET. But have you run DBMS_RESOURCE_MANAGER.CALIBRATE_IO? Have a look over Automatic Degree of Parallelism in 11.2.0.2 [ID 1269321.1] to see if you might be limiting yourself parallel-wise because the database has no idea what your IO subsystem is capable of. Note that they do not mention workload system stats in this context. I couldn’t find verification that these play no part in DOP, but this note seems to suggest the values in DBA_RSRC_IO_CALIBRATE play a much more significant role now. Following a link about a bug (10180307) in 11.2.0.2 and below, older versions of the CALIBRATE_IO procedure could produce unpredictable results. But more important was the comment that “The per process maximum throughput (MAX_PMBPS) value [might be] too large, resulting in a low DOP while running AutoDOP.” We confirmed this by allowing CALIBRATE_IO to run for about 10 minutes and checking the results. What we saw was 31K IOPS, 328 MB/s total, 334 MB/s per process, and a latency of 0. Interesting numbers, but the explain plan still said the computed DOP was 1. So what does Oracle suggest you do if you don’t like the parallelism? Cheat and set the values manually. According to the same note, start with: