The most expensive CPUs in your data centre aren't the ones doing the most work – they're the ones sitting idle waiting for storage. Here's why I/O latency is a hidden CPU tax.
The Most Expensive CPUs You Own

The most expensive CPUs in your data centre aren't the ones doing the most work – they're the ones sitting idle waiting for storage. Here's why I/O latency is a hidden CPU tax.

Oracle RAC is sold as a high-availability solution, but its real cost – in licenses, complexity and the hidden assumption that losing a node doesn’t count as an outage – is rarely made explicit.

Oracle database licensing is eye-wateringly expensive per CPU core – and storage costs, often seen as prohibitive, represent a surprisingly small fraction of the total three-year spend.

Putting Oracle redo logs on SSD is a common reflex response to slow databases – but it usually misdiagnoses the problem, and SSDs handle write-heavy sequential workloads worse than you might expect.

IOPS figures dominate flash storage marketing, but for databases latency is the metric that matters – high IOPS at unpredictable latency deliver no real-world value.

NAND flash development is driven by the consumer market – not the enterprise. The question to ask any flash vendor isn't "how fast?" but "where's your innovation?"

Not every database benefits from flash storage – knowing when it matters requires understanding how much I/O your workload generates, how random it is and how much latency is already costing you.

Disk I/O forces a choice between random and sequential access – and that choice defines whether latency compounds or disappears. Flash makes the distinction irrelevant.
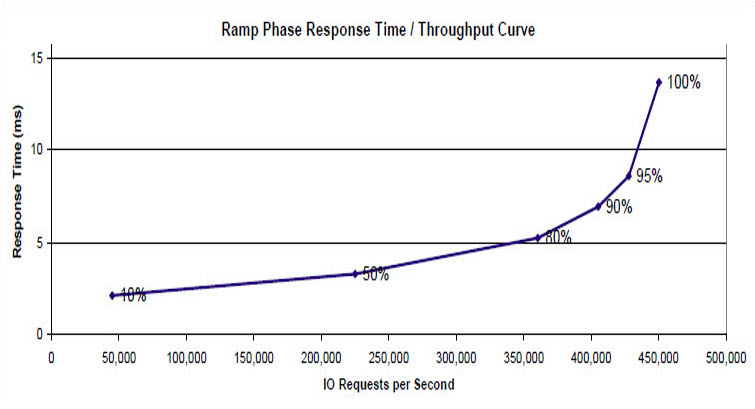
Latency, IOPS and bandwidth are the three properties that define any storage system – understanding how they relate to each other is the first step to knowing what your database actually needs.

Database performance problems are rarely solved by faster CPUs alone – the real issue is imbalance between resources, and disk latency is the silent bottleneck that flash storage changes.
