All Flash Arrays: Scale Up vs Scale Out (Part 2)
November 1, 2017 Leave a comment

In the first post on the subject of Scale Up versus Scale Out, we looked at the reasons why scalability is a key requirement for storage platforms, as well as discussing the limits of Scale Up only architectures, i.e. systems where more capacity is added to the same fixed number of controllers. In this article, we look at the alternative architecture known as Scale Out.
Scale Out – Adding Performance
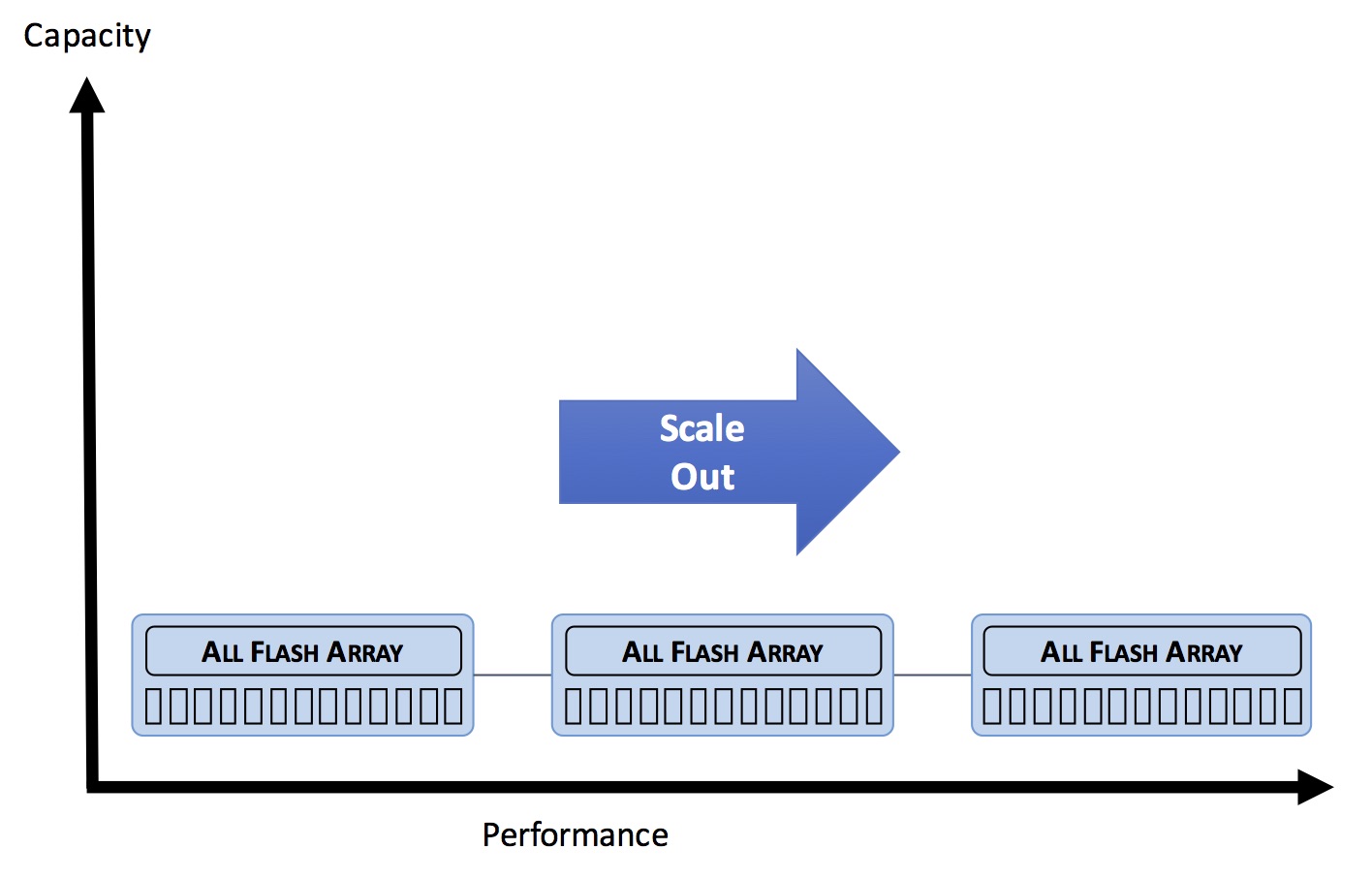 In a scale out architecture, the possibility exists to add more storage controllers, thereby adding more performance capability. You may remember that the performance of a storage array is approximately proportional to the number of (and power of) its storage controllers, while the capacity is determined by the amount of flash or SSD media addressed by those controllers.
In a scale out architecture, the possibility exists to add more storage controllers, thereby adding more performance capability. You may remember that the performance of a storage array is approximately proportional to the number of (and power of) its storage controllers, while the capacity is determined by the amount of flash or SSD media addressed by those controllers.
In this scenario, the base model typically consists of a pair of controllers (after all, at least two are required to provide resiliency). Most scale-up-capable storage arrays work by adding more pairs of these controllers, which are considered indivisible units and have names like “K-Block” (Kaminario K2) or “X-Brick” (DellEMC XtremIO). For now, let’s just call them controller pairs.
There are a number of technical challenges to overcome when building a system which can scale out. In the first post, we covered Active/Passive solutions, where only one controller processes I/O from the underlying media. In this scenario, the performance limitations are determined by the characteristics of the single active node – with the remaining (passive) node simply waiting to spring into action in the event of a failover. Clearly this type of architecture makes less sense as the number of nodes increases above two, since the additional nodes will also be passive and therefore adding little benefit.
Scale out architectures, then, typically employ an active/active solution whereby each controller contributes more performance capacity as it joins the system. And that means building a high-availability cluster, with all of the associated cluster management technologies that entails (failover, virtual IPs, protection against split brain scenarios, etc). No wonder some vendors stick to Scale Up only.
Of course, the biggest issue with a Scale Out only architecture is the question of what happens when additional capacity needs to be added. The answer is that another controller or set of controllers must be added too, complete with their attached storage media – but the controllers are an expensive and unnecessary addition if the only requirement is simply more capacity.
Scale Up and Scale Out – The Perfect Solution?
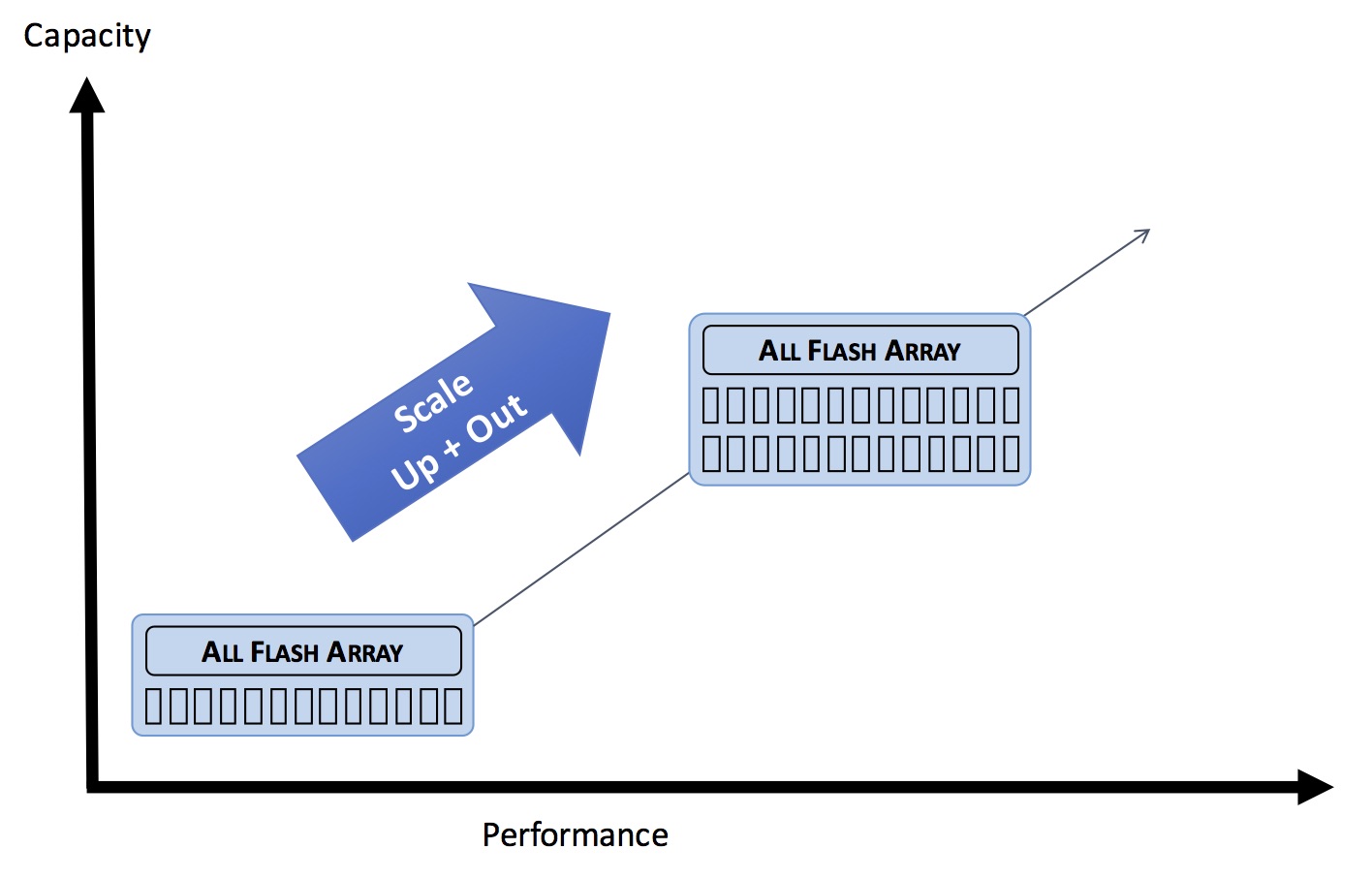 So what we’ve seen here is that a Scale Up architecture allows for more capacity to be added to existing controllers, while a Scale Out architecture allows for more performance to be added to existing capacity. It would therefore seem logical that the ultimate goal is to build a system which can (independently) scale both up and out. Scaling up allows more capacity to be added without the cost of more controllers. Scaling out allows more performance (controllers) to be added when required. And thus the characteristics of the storage platform can be extended in either of these two dimensions as needed. Perfect?
So what we’ve seen here is that a Scale Up architecture allows for more capacity to be added to existing controllers, while a Scale Out architecture allows for more performance to be added to existing capacity. It would therefore seem logical that the ultimate goal is to build a system which can (independently) scale both up and out. Scaling up allows more capacity to be added without the cost of more controllers. Scaling out allows more performance (controllers) to be added when required. And thus the characteristics of the storage platform can be extended in either of these two dimensions as needed. Perfect?
Arrays which can support both scale up and scale out have been surprisingly rare in the All Flash market so far, but they do exist. The concept is simple: customers that purchase storage typically do so over a three to five year period. Most people simply cannot guess how their requirements will change in that period of time… more users, more customers, more data? Yes, probably – but how much and over what time period? Choosing an architecture which allows independent (non-disruptive) scale of both capacity and performance insures against the risk associated with capacity planning, while also allowing customers to start off by purchasing only what they need today and then expanding at their own pace. Sounds a bit like cloud computing when you put it like that, doesn’t it?
Which conveniently leads us to…
The Future: Dynamically Composable / Disaggregated Storage?
None of us know how the future will look, especially in the technology industry. But one vision of the future comes from my employer, Kaminario, who is one of a number of companies exploring the concept of composable infrastructure. I think this is a very interesting new direction, which is why I’m writing about it here – but since I’m an employee of this vendor I must first give you a mandatory sales warning and you should treat the next paragraphs with a healthy dose of “well he would say that, wouldn’t he?”
In a dynamically composable storage environment, the two elements we have been discussing above (storage controllers and storage media) become completely disaggregated so that any shelf of media can be addressed by any set of controllers. These sets of systems can then be dynamically composed, so that – out of a set of multiple shelves of media and storage controllers – subsets of the two can be brought together to form virtual private arrays designed to serve specific applications.

© 2017 Kaminario
If you think about the potential of this method of presentation, it opens up many possibilities. For example, the dynamic and non-disruptive reallocation of storage resources offers customers the ability to constantly adapt to unpredictable workloads. Furthermore, concepts from AI can be used to automate this reallocation and even predict changes to requirements in advance.
This is useful for any customer with a complex estate of mixed workloads, but it’s incredibly useful to Cloud Service Providers and MSPs. After all, these organisations have no knowledge of what their customers are doing on their systems or what they will do in the future, so the ability to dynamically adapt performance and capacity requirements could provide a competitive edge.
Conclusion
We all know that I.T. is full of buzzwords, like agility or transformation. Is scalability another one? Maybe it’s in danger of becoming one. But if you think about it, one of the fundamental characteristics of any platform is its ability to scale. It essentially defines the limitations of the platform that you may meet as you grow – and growth is pretty much the point of any business. So take the time to understand what scale actually means in a storage context and you might avoid learning about those limitations the hard way…








